Azure ML Pipelines and MLOps with GitHub Actions – Part 2
It is usually better to start at the beginning so you might want to head over to Part 1 if you missed it.
In Part 2 I will focus on managing the pipeline run with the “run context” and then registering the model in a way that ties the model back to the pipeline, artifacts, and code that published it. In Part 3 I will conclude with pipeline schedules and GitHub Actions.
All of the source code can be found on my GitHub so don’t be shy to give it a star 🙂
Leveraging Run Context
Azure ML allows execution of a Python script in a container that can be sent/run on AML compute clusters instead of a local machine. This could be a data transformation script, a training script, or an inferencing script. The below examples shows how to do this for a simple training script (stand alone, in absence of a pipeline)
from azureml.core import Experiment
experiment_name = 'train-on-amlcompute'
experiment = Experiment(workspace = ws, name = experiment_name)
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory=project_folder,
script='train.py',
compute_target=cpu_cluster,
environment=myenv)
run = experiment.submit(config=src)These "runs" are executed via a submit command from an experiment. Being able to log information to the run from within the script itself (in the above example train.py) is key.
In this repo, iris_supervised_model.py leverages run context to log metrics, tables, and properties.
run = Run.get_context()
This is the magic line that connects a vanilla Python script to the context of the run, inside the experiment, inside the Azure ML workspace.
Now, metrics can be logged
run.log("accuracy",best_score)
and tables
run.log_confusion_matrix('Confusion matrix '+name, confusion_matrix(Y_train, model.predict(X_train)))
See this sample notebook for all the things logging.
TIP When relying on run context of Azure ML (such as environment variables being passed in from the driver script) performing the following check early in the script can allow defaults to be set for anything that would have been passed in. This allows for local testing which is a time saver.
if (run.id.startswith('OfflineRun')):
os.environ['AZUREML_DATAREFERENCE_irisdata'] = '.\sample_data.csv'
os.environ['AZUREML_DATAREFERENCE_model_output'] = '.\model_output'
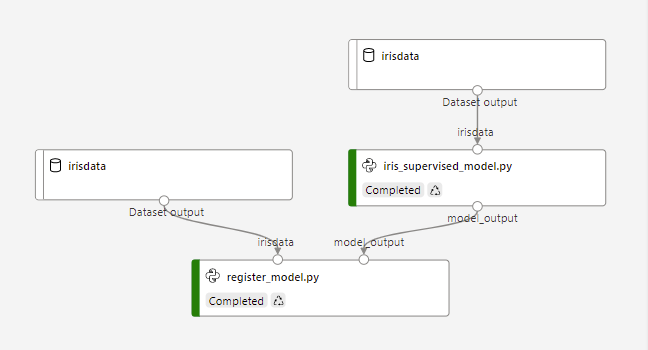
Managing the pipeline execution
In a pipeline, each run is at the step level, or a child of a parent run which is the pipeline itself.
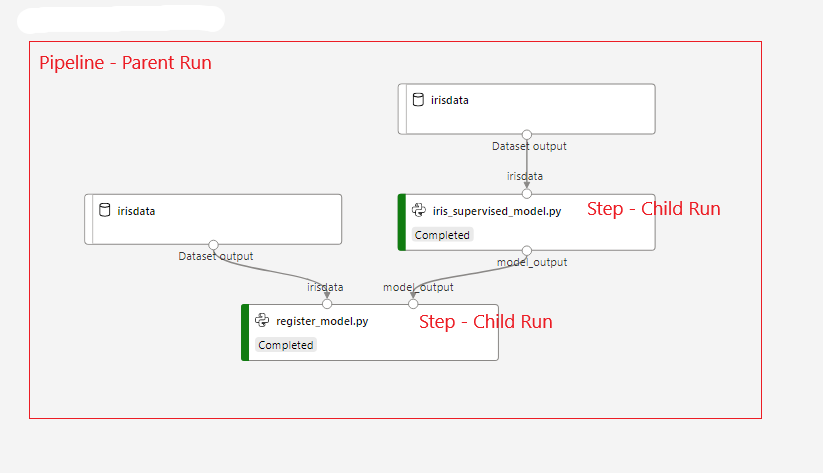
It may be best to log important metrics or properties at the pipeline level rather than at the step level (or both). run.parent will get the parent run context. The code below sets the two properties by passing in a dictionary as the parameter and those same values on two tags as well.
run.parent.add_properties({'best_model':best_model[0],'accuracy':best_score})
run.parent.tag("best_model",best_model[0])
run.parent.tag("accuracy",best_score)
Properties are immutable while tags are not, however tags are more predominant in the Azure ML Run UI so they are easier to read.
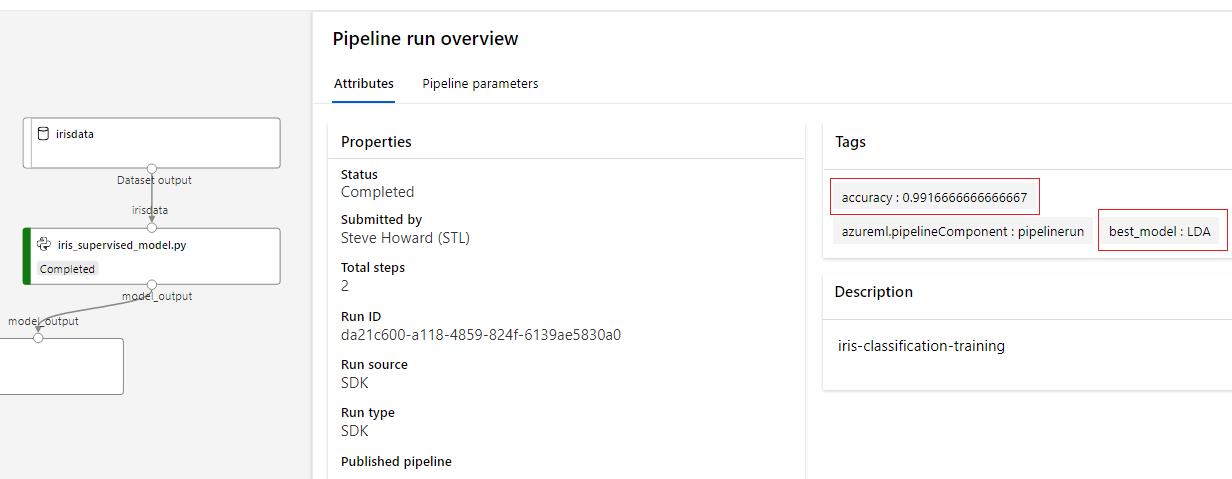
To review the added properties click "Raw JSON" under "see all properties".
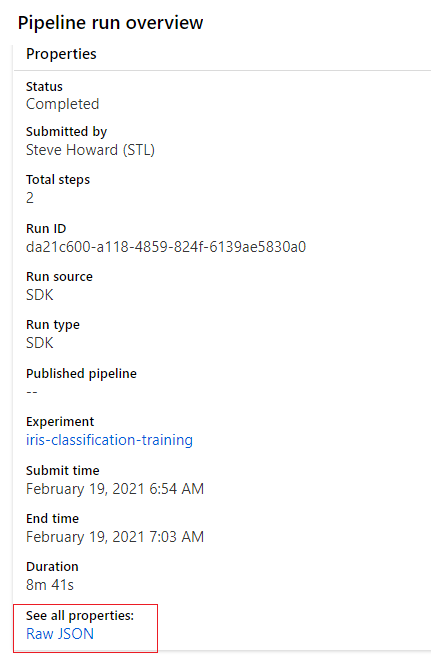

Now that the results of the training are published to the parent pipeline tags (and properties), they can be used to control what happens in execution of later steps. In register_model.py, the accuracy score is going to control if this model will be registered or not.
Model Registration
The model artifact should be registered as it allows "one click" deployment for real time inferencing hosted on AKS or ACI. Even if the intention is to use it for batch inferencing with Azure ML pipelines it is a more organized way as shown below to keep full context of how the model was built verse just storing the pickle file off in a cloud storage location.
In context of this example pipeline, training has been completed in iris_supervised_model.py. The best model accuracy has been recorded in the tags of the pipeline run.
In the next step of the pipeline register_model.py, retrieve the parent pipeline run context with parentrun = run.parent and review the tags that have been set.
The below code block shows getting the accuracy score from the tag dictionary for the current pipeline run, but also an alternative method to interegate previous steps in the pipeline to retrieve the tags by using parentrun.get_children()
tagsdict = parentrun.get_tags()
if (tagsdict.get("best_model")) != None:
model_type = tagsdict['best_model']
model_accuracy = float(tagsdict['accuracy'])
training_run_id = parentrun.id
else:
for step in parentrun.get_children():
print("Outputs of step " + step.name)
if step.name == training_step_name:
tagsdict = step.get_tags()
model_type = tagsdict['best_model']
model_accuracy = float(tagsdict['accuracy'])
training_run_id = step.idThe model can be registered directly to the workspace, but the context of how the model was built is then disconnected from the training pipeline. Instead, the model will be registered from the pipeline run object. To do this the model artifact (model.pkl file) needs to be uploaded to the parent run.
# to register a model to a run, the file has to be uploaded to that run first.
model_output = os.environ['AZUREML_DATAREFERENCE_model_output']
parentrun.upload_file('model.pkl',model_output+'/model.pkl')Next, see if the model name is already registered. If so, record the accuracy score of the previous model to compare against the new model. If this is the first time the model has been trained it won’t exist in the registry so set the accuracy to beat equal to 0.
try:
model = Model(ws, model_name)
acc_to_beat = float(model.properties["accuracy"])
except:
acc_to_beat = 0Compare the new model accuracy with the previous model accuracy to beat and if the model is better, register it. Note: the model is being registered via parentrun.register_model and not Model.register_model. This is important as it nicely ties the registered model and artifact back to all the context of how it was created.
if model_accuracy > acc_to_beat:
print("model is better, registering")
# Registering the model to the parent run (the pipeline). The entire pipeline encapsulates the training process.
model = parentrun.register_model(
model_name=model_name,
model_path=model_path,
model_framework=Model.Framework.SCIKITLEARN,
model_framework_version=sklearn.__version__,
sample_input_dataset=dataset,
resource_configuration=ResourceConfiguration(cpu=1, memory_in_gb=0.5),
description='basic iris classification',
tags={'quality': 'good', 'type': 'classification'})Set additional properties for accuracy and model_type so that the next time training is ran the current accuracy will be compared against that model (just like above)
model.add_properties({"accuracy":model_accuracy,"model_type":model_type})
model.add_tags({"accuracy":model_accuracy,"model_type":model_type})Access the run logs, outputs, code snapshots from registered model
In the model registry, when registering from the run itself, it hyperlinks to the run id.
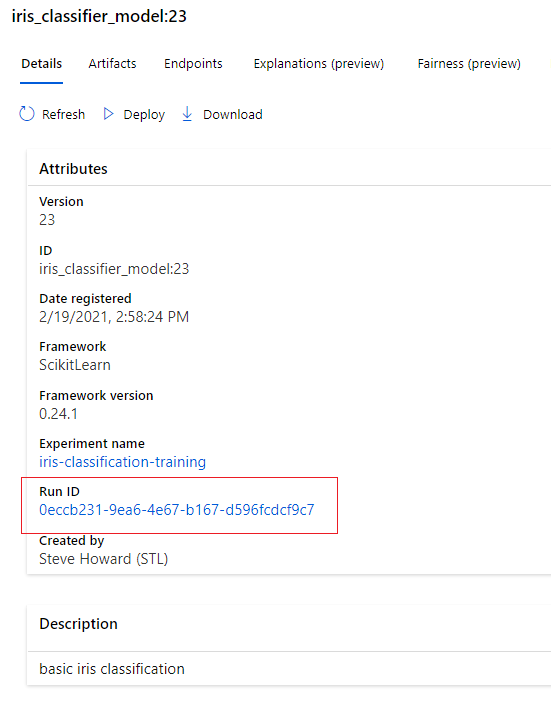
This links back to the pipeline run.
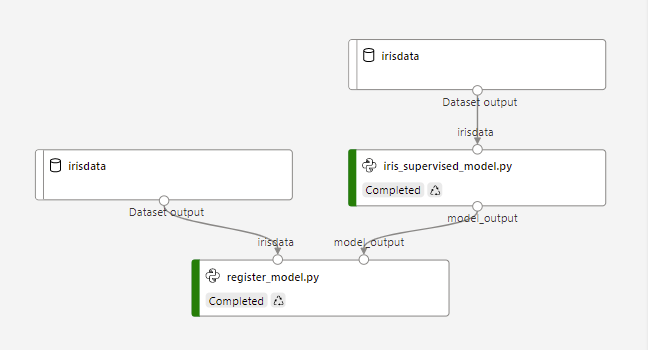
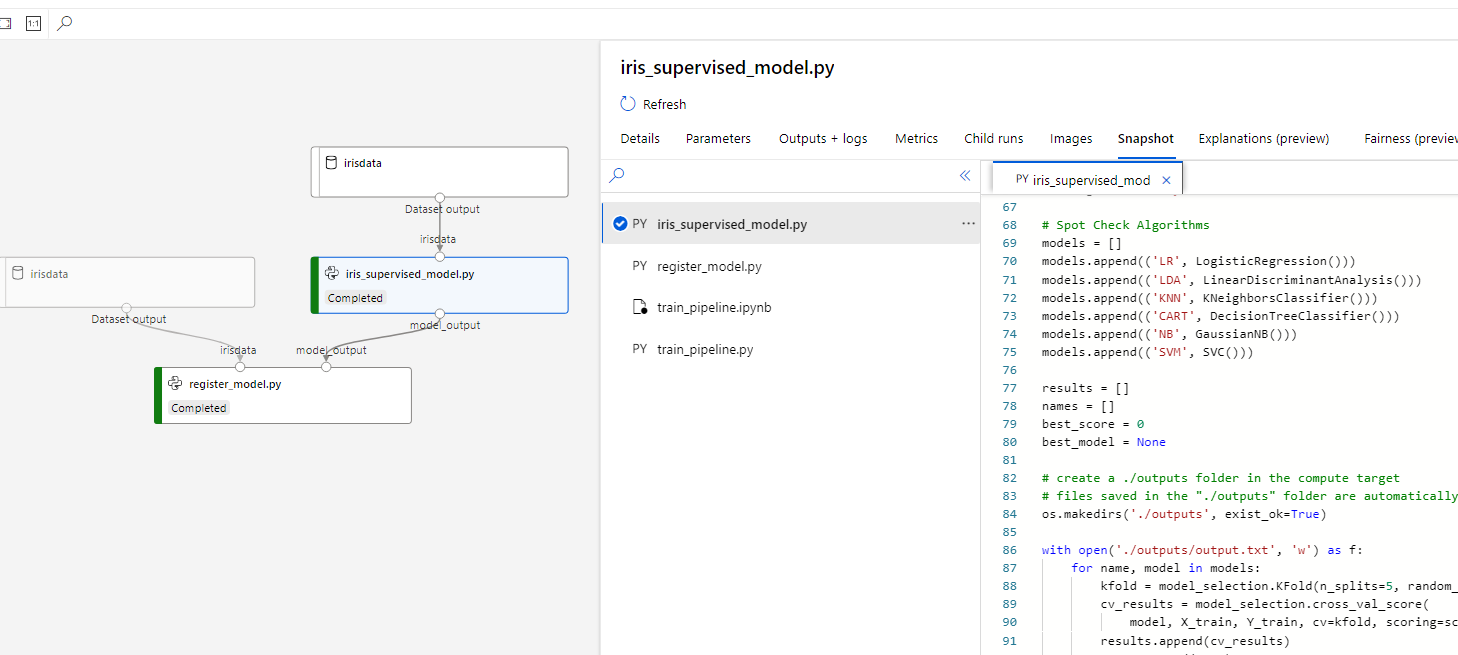
Notice that when clicking on the iris_supervised_model.py step, there is access to the outputs/logs, metrics, and even the snapshots of the code used to generate the model artifact that is registered.
Conclusion
Registering the model from the pipeline run gives complete context of how the model was built and registered! Its sets up real time and batch inferencing deployment as next steps.
Up Next Part 3