I have been working on customer projects with Azure ML pretty regularly over the last two years. Some common challenges:
- Microsoft highly promotes the AKS deployment for real time inference, yet most of the time customers are still looking for an effective way to do batch scoring.
- When customers leverage Azure ML pipelines for batch processes they struggle with the concept of pushing datasets and files between steps. This erodes the true power of splitting an ML process into steps.
- MLOps is hard and overwhelming.
This is not a “start from the beginning” blog post. This is going to assume that you have familiarity with Azure ML If you are not, the sample notebooks are seriously EXCELLENT! However, they seem to get you 90% there but miss out on implementation details that are key for success.
The scenario I am using below and can be found on my GitHub. It is an Azure Pipeline that trains several iris classification models. It picks the best one and logs it. In the next pipeline step, if that model is better than the previous training run, it will register the model. This training pipeline can be put on a schedule or it can be triggered from a code check in. In this case, from a GitHub action.
In a later blog post, i will discuss in more detail the model registration process (some production tips there) and the GitHub action, but I will start with properly passing datasets and files between steps.
Passing datasets and files between steps
Other than a few blogs I have found on the internet, instructions on how to properly pass files or datasets between steps are hard to find.
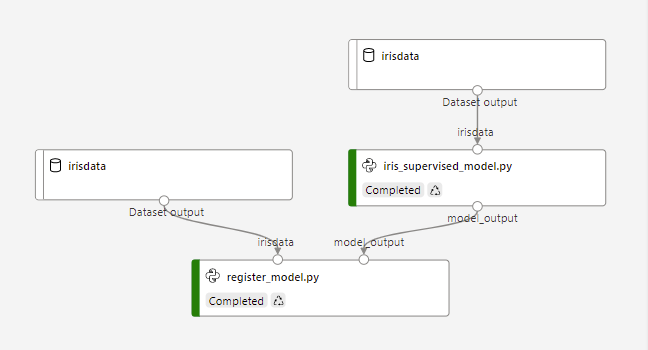
In the above image you can see that irisdata is passed into iris_supervised_model.py and then model_output is the output. When you define the pipeline in the driver script, the input data is a DataReference object and any data passed between steps is a PipelineData object.
from azureml.core.datastore import Datastore
from azureml.data.data_reference import DataReference
ds = ws.get_default_datastore()
print("Default Blobstore's name: {}".format(ds.name))
dataset_ref = DataReference(
datastore=ds,
data_reference_name='irisdata',
path_on_datastore="data/sample_data.csv")
print("DataReference object created")from azureml.pipeline.core import Pipeline, PipelineData
model_output = PipelineData("model_output",datastore=ds)
print("PipelineData object created for models")In the PythonScriptStep, utilize the input and output parameters.
from azureml.pipeline.steps import PythonScriptStep
trainingScript = PythonScriptStep(
script_name="iris_supervised_model.py",
inputs=[dataset_ref],
outputs=[model_output],
compute_target=aml_compute,
source_directory="./azureml",
runconfig=run_config
)Simply pass the “model_output” from outputs as input to the next step (the register_model.py that will be a focus of the next blog post) and so on.
Using these references in the script
When you submit a pipeline job to run, a container is created and all the files in the source_directory specified in the PythonScriptStep are imported into the container. The input and outputs effectively become mount points for blob storage to that container. In the iris_supervised_model.py script step this mount point is accessible via an environment variable that looks like the below.
os.environ['AZUREML_DATAREFERENCE_irisdata']This is also the same environment variable format used for the output location (the PipelineData object) which appears to be a randomly created storage location given to you from AzureML.
mounted_output_path = os.environ['AZUREML_DATAREFERENCE_model_output']Looking at the mounted_output_path variable above gives a location like: mnt/batch/tasks/shared/LS_root/jobs/amlworkspacesjh/azureml/715a1dca-fafc-4899-ae78-ffffffffffff/mounts/workspaceblobstore/azureml/71ab64d9-bc4c-4b74-a5a5-ffffffffffff/model_output
You should be able to treat these environment variables as a file location just like a local path. So for the irisdata which was a csv file in the data reference you can read it like normal.
df = pd.read_csv(os.environ['AZUREML_DATAREFERENCE_irisdata'], names=column_headers)For the model_output we pickle the model file and save it to the mounted_output_path.
pkl_filename = "model.pkl"
mounted_output_path = os.environ['AZUREML_DATAREFERENCE_model_output']
with open(os.path.join(mounted_output_path, pkl_filename), 'wb') as file:
pickle.dump(best_model[1], file)Now look into register_model.py, we utilize the PipelineData object (model_output) as our input and reference the same environment variable as in iris_supervised_model.py
mounted_output_path = os.environ['AZUREML_DATAREFERENCE_model_output']
print("model path",model_output)
print("files in model path",os.listdir(path=model_output))In the file list, model.pkl is there right where it was created in the training script.
Conclusion
The ability to pass data between pipeline steps is pretty easy, but the documentation on using the magic “AZUREML_DATAREFERENCE_***” environment variables is lacking in most of the sample notebooks I have found. Just remember that these are mount points and can be interacted with just like local files basically.
Up next, Part 2
The “where have I been?” footnote
It has been 21 months since my last blog post. My role at Microsoft has led me to focus much more on cloud data services for only a couple of customers. I loved to blog about Power BI but I just haven’t been in that space for awhile as my day to day responsibilities were handed over to the much more capable @notaboutthecell. I have been working a lot on real time stream processing (with Databricks / Cosmos DB / Azure Functions) and ML engineering activities with Azure ML. Blog posts have been difficult as so much of my work is implementation oriented and it is hard to recreate everything in a publicly sharable way.
Or maybe i have just been lazy 🙂
Anyway, I am sure that the blog posts in my future are probably going to be more narrow in application and probably won’t be “marathon reads” that explain everything in detail but hopefully enough to connect the dots for the people who need it.

One comment