Azure ML Pipelines and MLOps with GitHub Actions – Part 3
As this is Part 3, you might want to review Part 1 and Part 2 for context if you haven’t yet.
In Part 3, I will finally focus on the GitHub action.
All of the code for this can be found on my GitHub.
How to run the training process from GitHub Action
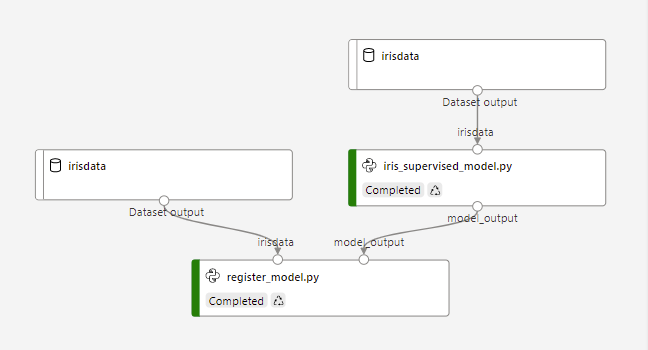
To put the "Ops" in "MLOps" the pipeline execution should be automated whenever possible. The scenario being used in this repository is when code is checked in, the training pipeline is automatically kicked off from a GitHub Action and if the newly trained model has a higher accuracy than the previous model, then it will be registered in the model repository.
To review, iris_supervised_model.py does the training and register_model.py obviously registers the model. The pipeline that runs these two steps is built and executed from train_pipeline.py. So it is this train_pipeline.py (also referred to in this repository documentation as the driver script) that needs to be executed from a GitHub action.
Creating the GitHub Action
Actions allow for automation of processes. They are YAML scripts.

I won’t pretend to be an expert on YAML or the action schema, but i pulled a sample and made some modifications. Action scripts should be placed in .github/workflows directory of the repo.
name: iristrain
on: [push]
jobs:
run:
runs-on: [ubuntu-latest]
container: docker://dvcorg/cml-py3:latest
steps:
- uses: actions/checkout@v2
- name: train_pipeline
env:
repo_token: ${{ secrets.GITHUB_TOKEN }}
AZUREML_CLIENTID: ${{secrets.AZUREML_CLIENTID}}
AZUREML_TENANTID: ${{secrets.AZUREML_TENANTID}}
AZUREML_SECRET: ${{secrets.AZUREML_SECRET}}
AZUREML_SUBSCRIPTION: ${{secrets.AZUREML_SUBSCRIPTION}}
AZUREML_RESOURCE_GROUP: ${{secrets.AZUREML_RESOURCE_GROUP}}
AZUREML_WORKSPACE: ${{secrets.AZUREML_WORKSPACE}}
run: |
# Your ML workflow goes here
pip install -r requirements.txt
python azureml/train_pipeline.pyThe above code shows that on [push] so when any code is pushed to the repository, the jobs: will be performed. Unique to this example is the environment variables env: that are all populated from GitHub secrets. They are passed into the train_pipeline.py script which is invoked with the last line of the yaml file above. Any libraries required to run the python script need to be installed first on the container therefore the pip install -r requirements.txt is there. The current requirements.txt has more than what is needed to run the script, specifically azureml-sdk is the entry required for this scenario.
Service Principal Authentication to Azure ML
Unlike building a pipeline and running it from a Jupyter notebook interactively, to use automation the credentials to login to Azure ML have to be stored. Using an Azure Active Directory user principal is the right way to do this.
Creating a service principal in Azure will likely require elevated permissions in Azure. Work with your Azure administrator to enable this.
In this notebook there is a section for Service Principal Authentication that walks through the setup. Once a service principal is created, it can be used from the train_pipeline.py script.
from azureml.core import Workspace
from azureml.core.authentication import ServicePrincipalAuthentication
svc_pr_password = os.environ.get("AZUREML_SECRET")
svc_pr = ServicePrincipalAuthentication(
tenant_id=os.environ['AZUREML_TENANTID'],
service_principal_id=os.environ['AZUREML_CLIENTID'],
service_principal_password=svc_pr_password)
ws = Workspace(
subscription_id=os.environ['AZUREML_SUBSCRIPTION'],
resource_group=os.environ['AZUREML_RESOURCE_GROUP'],
workspace_name=os.environ['AZUREML_WORKSPACE'],
auth=svc_pr
)Note the heavy use of environment variables. This is to ensure that credentials and other private variables are not stored clear text in this repo for the world to see. These are being passed in from the action yaml shown above.
More comprehensive information on Azure ML authentication can be found here
GitHub Secrets
The above section highlights the environment variables being used. These variables are initiated from the GitHub repositories action secrets.
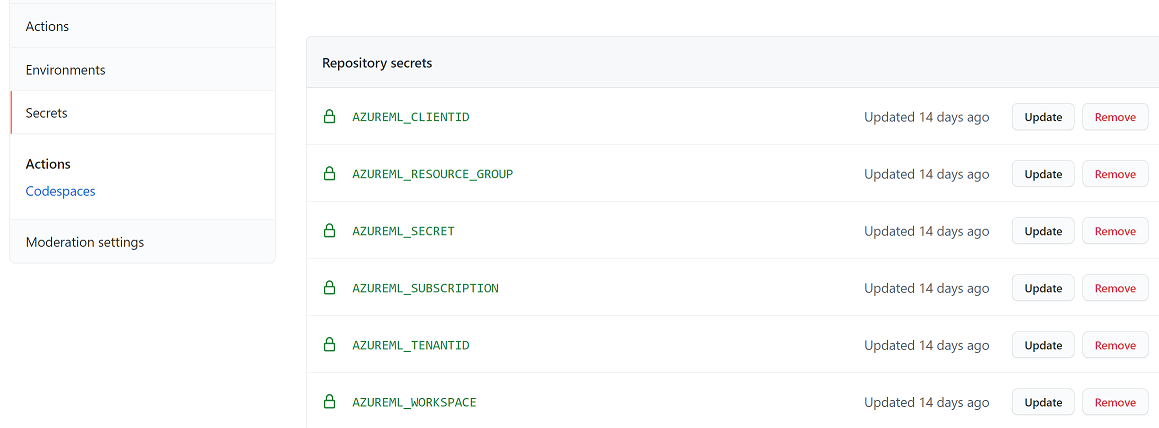
These secrets are created in the repository from the "Settings" tab. In the "Secrets" section, click the "new repository secret" button to add a secret.
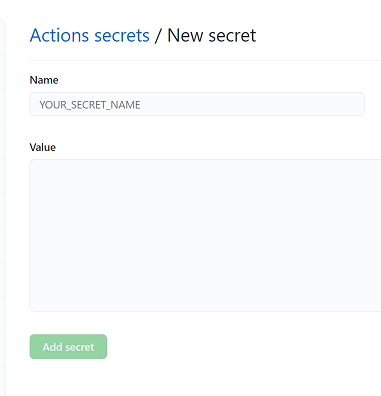
It should be obvious that the secret names need to match the secrets given in the yaml action script: ${{secrets.AZUREML_CLIENTID}}.
Invoking the GitHub Action
Any change to the source code based on this simple action definition will invoke the train_pipeline.py which defines and then submits the iris_train_pipeline with the snip of code below.
iris_train_pipeline = Pipeline(workspace=ws, steps=[trainingScript,registerModelStep])
print ("Pipeline is built")
exp = Experiment(ws,experiment_name)
exp.set_tags({'automl':'no','working':'no'})
pipeline_run1 = exp.submit(iris_train_pipeline)
print("Pipeline is submitted for execution")
pipeline_run1.wait_for_completion()This will happen from master or a branch. To see the action in action, in iris_supervised_model.py change the n_splits from 5 to 3.

Do a commit and push. Note: I have been using VSCode. The Python editor and GitHub integration is legit!
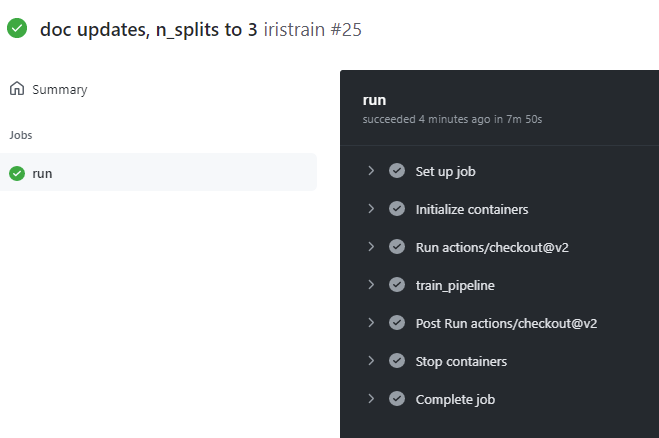
On the Actions tab of the repo, a new action is now visible with a "yellow" icon to indicate "in progress"
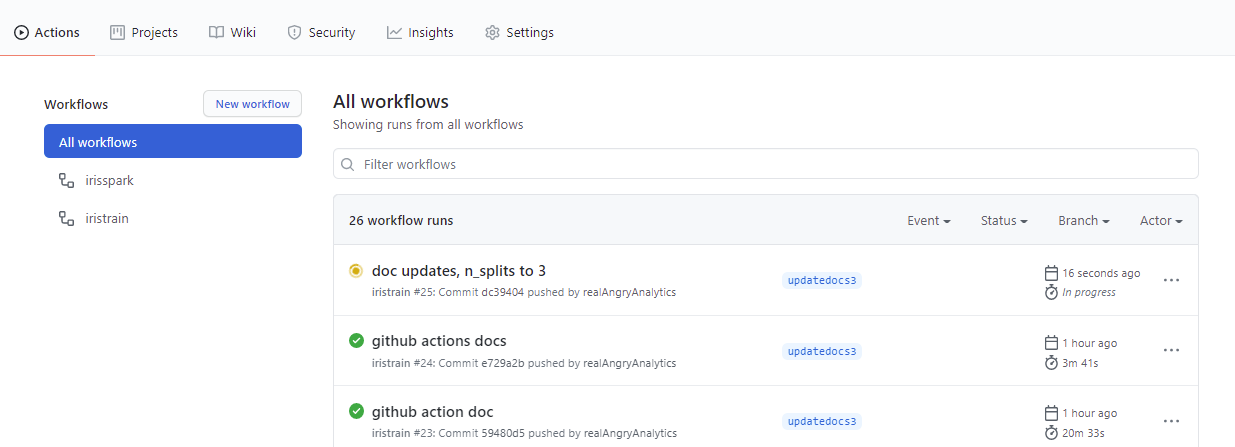
Click on the run to see the details
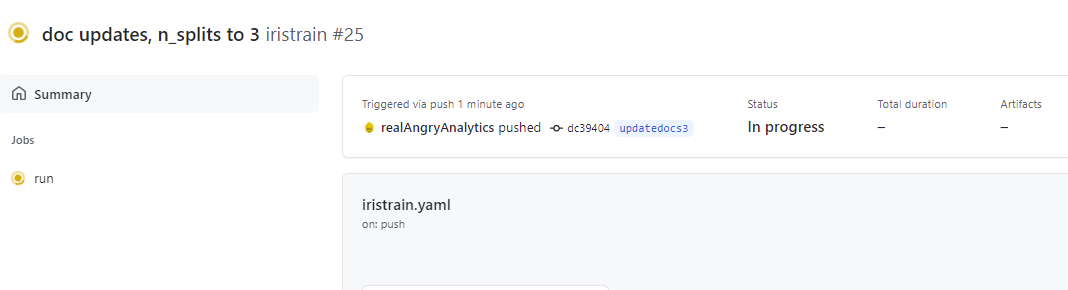
In the details section click on the run itself and the logs can be reviewed in real time. First GitHub is acquiring a container image to install the necessary python configuration to run the train_pipeline.py script.
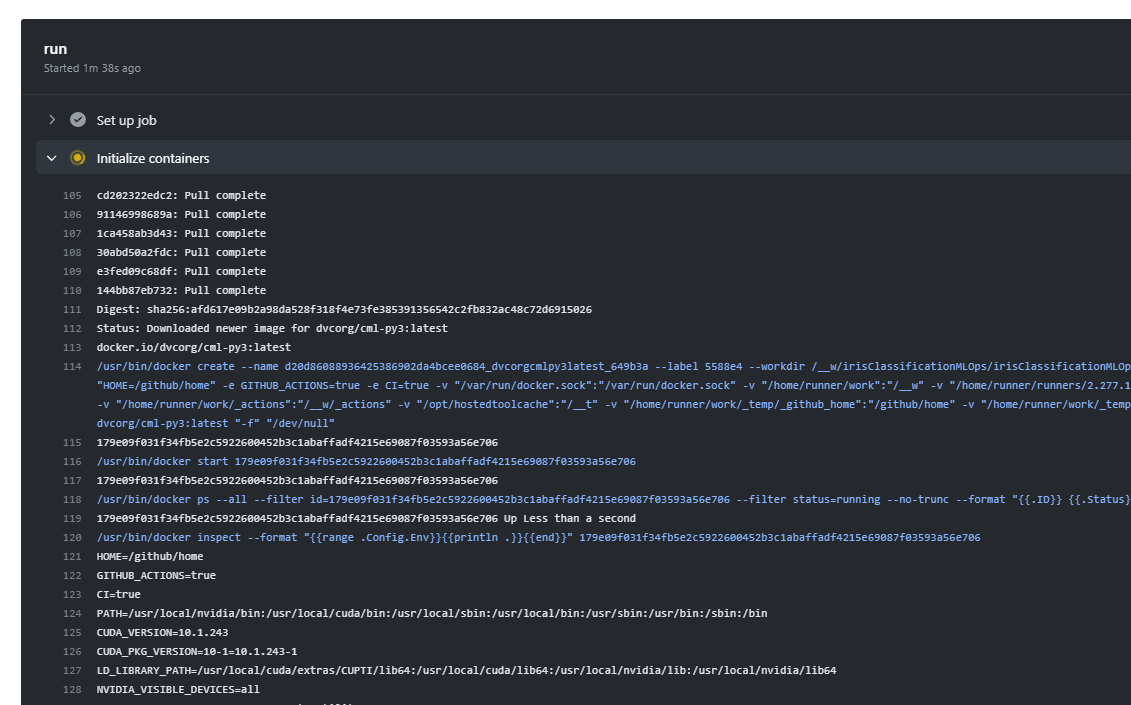
Once the image is acquired, it kicks off the Azure ML Pipeline which can be reviewed in Azure ML Studio
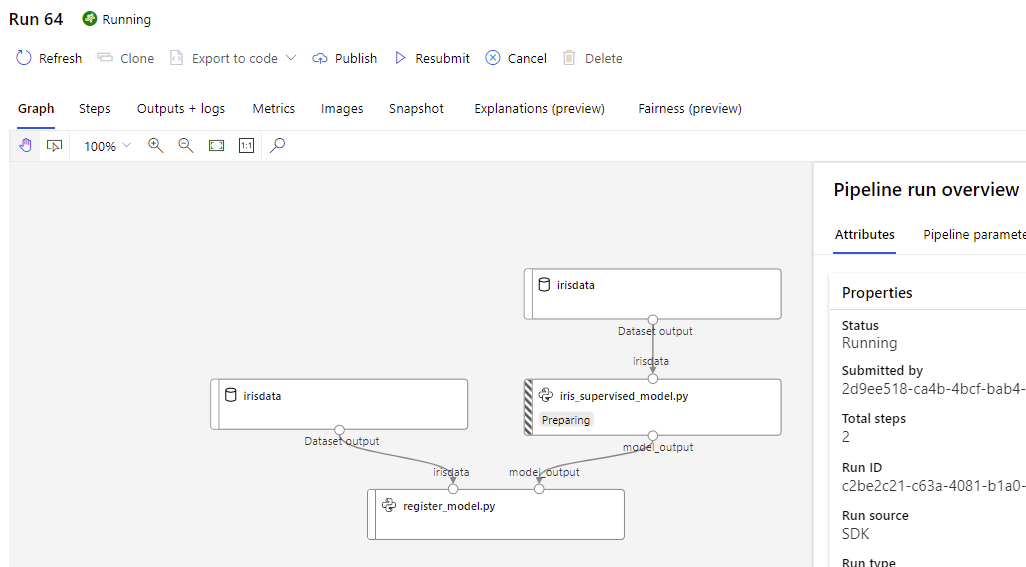
pipeline_run1.wait_for_completion() is an important line in train_pipeline.py that keeps the script from completing until the Azure ML pipeline completes. Without this line the action will finish while the pipeline is still running. This may be desired depending on the scenario.
The logged pipeline outputs will be displayed in the run output.
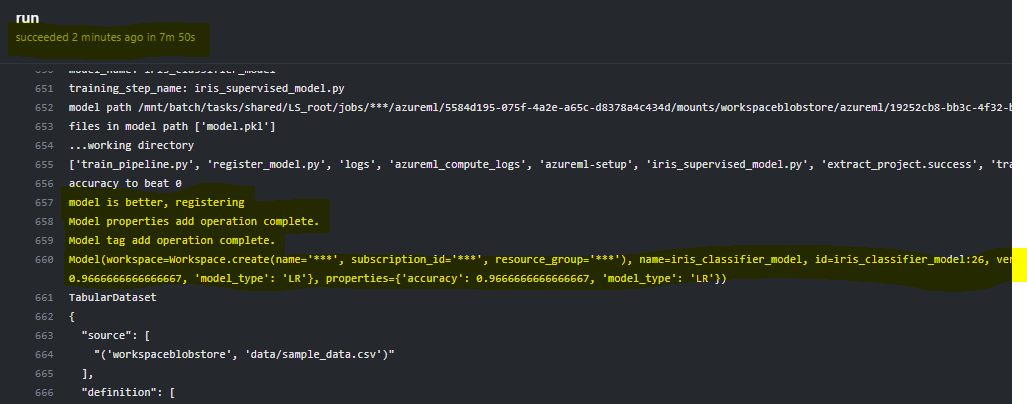
When it is complete, the status will show green.
Conclusion
That is it. Now your training process is fully automated based on code check in. And yes, YAML is still the most awful definition language but you have to just shut up and deal with it 🙂