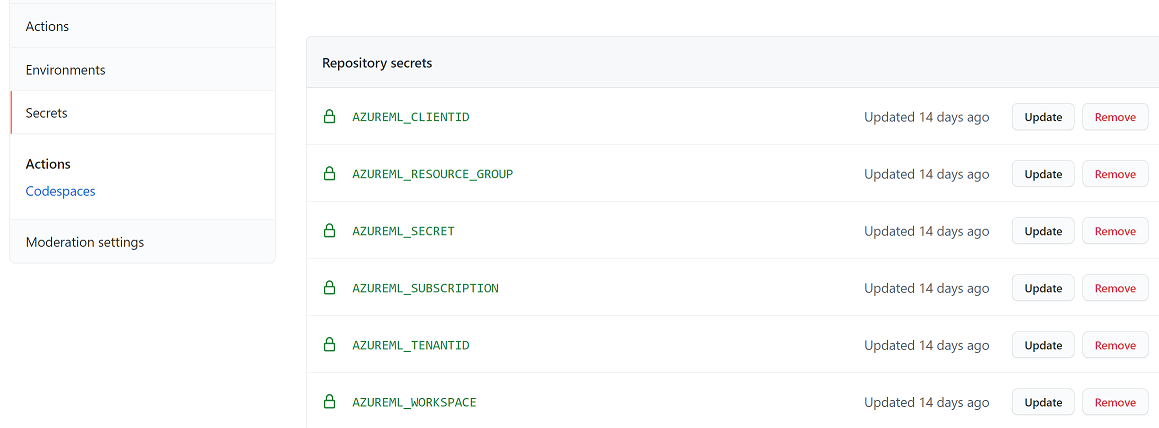
I am closing out 2017 with a refreshing project that has led me away from Power BI for a bit. However, even for the Power BI community, I think the below information is valuable because at some point, you are going to run into a file that even the M language (Power BI Query Editor) is going to really have a hard time parsing.

For many of you, its still a flat file world where much of your data is being dropped via an FTP server and then you have a process that parses it and puts it in your data store. I recently was working with a file format that I have no idea why someone thought it was a good idea, but nonetheless, i am forced to parse the data. It looks like this:
display > e1
Site Name : Chicago IL Seq Number : 111
Mile Mrkr : 304.40 DB Index # : 171
Direction : South Arrival : 00:02 09-22-2017
Speed In/Out: 33/18 MPH Departure : 00:03:45
Slow Speed : 38 MPH Approach Speed : 0 MPH
Approach Length: ~0.0 Feet
Amb Temp : 81 F Battery Voltage: 12.03
Axles : 5 Truck Length : 56.0 Feet
Alarms : 0 Cars : 1
Integ Fails : 0 Gate A Cnt : 1
System Warn : 0 Gate B Cnt : 1
Weight : 72000
HBD Filter : 13 Point Median Filter
Car Axle Weight Ch1 Ch2
Num Num (LBS) (F) (F) Alarms
-------------------------------------------------------------- Weight Units = LBS
1 1 17000.0 N/A N/A
2 17000.0 N/A N/A
3 17000.0 N/A N/A
4 17000.0 0 0
5 17000.0 0 0
This data simulates truck weigh-in station data. There is a lot of “header” information followed by some “line” items.
Just think for a moment how you would approach parsing this data? Even in Power BI, this would be extremely brittle if we are counting spaces and making assumptions on field names.
What if a system upgrade effecting the fields in the file is rolled out to the truck weigh stations over the course of several months? Slight changes to format, spacing, field names, etc… could all break your process.

Regex to the Rescue
In my career as a developer, I never bothered to understand the value of regular expressions (regex). With this formatted file I now see that they can save my life (well, that may be dramatic, but they can at least save me from a very brittle pre-processing implementation)
For anyone unfamiliar with regex, a regular expression is simply a special text string for describing a search pattern. The problem is, they are extremely cryptic and scary looking and you want to immediately run away from them and find a more understandable way to solve your text string problem. For instance, a regular expression that would find a number (integer or decimal) in a long string of characters would be defined as
What the heck is that?
The “d” represents any decimal digit in Unicode character category [Nd]. If you are only dealing with ASCII characters “[0-9]” would be the same thing. The “+” represents at least one instance of this pattern followed by (.d*) which identifies an explicit dot “.” followed by another d but this time with a “*” indicating that 0 to n instances of this section of the pattern unlike the first section that required at least 1 instance of a digit. Therefore this should result in true for both 18 as well as 18.12345. However, regex are greedy by default, meaning it expects the full pattern to be matched. So without adding the “?” to the end of the string, the above regex would NOT recognize 18 as a number. It would expect a decimal of some sort. Because we have included the “?” it will end the match pattern as long as the first part of the match was satisfied, therefore making 18 a valid number.
So, the regex was 11 characters and it took me a large paragraph to explain what is was doing. This is why they are under utilized for string processing. But if you are looking at it the other way, it only took 11 characters to represent this very descriptive pattern. Way cool in my book!
Regex language consistency
My example above was from Python. As i am a “data guy”, i find Python to have the most potential for meeting my needs. I grew up on C# and Java however so understanding regex may have some slight variations between languages. Some interesting links on this are below:
Stack Overflow: https://stackoverflow.com/questions/12739633/regex-standards-across-languages
language comparison on Wikipedia: https://en.wikipedia.org/wiki/Comparison_of_regular_expression_engines
Building a Parser using Regex
This file has all kinds of problems. Notice the value formats below:
Temperature: 81 F
Length: 56 Feet
Datetime: 00:02 09-22-2017
Time: 00:03:45
Speed: 33/18 MPH
In addition to text and numeric values, we also have to deal with these additional formats that should be treated as either numeric or datetime values.
I am going to use Python to parse this file and will use a “tokenizer” pattern discussed in the core Python documentation for the re (regex) library: https://docs.python.org/3.4/library/re.html
This pattern will allow us to assign a “type” to each pattern that is matched so we do not have to count spaces and try to look for explicitly named values which could break with any slight modifications to the file.
Below is a function that returns a named tuple with values for the type, the value, the line, and the column it was found in the string.
import re
import collections
Token = collections.namedtuple('Token', ['typ', 'value', 'line', 'column'])
def tokenize(line):
token_specification = [
('SPEED_IN_OUT', r'(d+(.d*)?/d+(.d*)?s{1}MPH)'), # speed with multiple values (ex. 15/10 MPH)
('SPEED', r'(d+(.d*)?s{1}MPH)'), # speed with one value (ex. 10 MPH)
('LENGTH', r'(d+(.d*)?s{1}Feet)'), # length in feet (ex. 10 Feet)
('TEMP', r'(d+(.d*)?s{1}[F])'), # Temperature in Fahrenheit (ex. 83 F)
('DATETIME', r'(d+:(d+(:d)*)*)+s+(d+-d+-d+)'), # Datetime value (ex. 00:00:00 12-12-2017)
('TIME', r'(d+:(d+(:d)*)*)+'), # time value only (ex. 00:02 or ex. 00:02:02)
('ID_W_NBR', r'(d+(.d*)?s([/w]+s?)+)'), # ID that is prefixed by a number
('NUMBER', r'd+(.d*)?'), # Integer or decimal number
('ID', r'([/w]+s?)+'), # Identifiers
('ASSIGN', r': '), # Assignment operator
('NEWLINE', r'n'), # Line endings
('SKIP', r'[ t]+'), # Skip over spaces and tabs
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
line_num = 1
line_start = 0
for match in re.finditer(tok_regex, line):
kind = match.lastgroup
value = match.group(kind)
if kind == 'NEWLINE':
line_start = match.end()
line_num += 1
elif kind == 'SKIP':
pass
else:
column = match.start() - line_start
token = Token(kind, value.strip(), line_num, column)
yield token
In my list of token specifications, i have included the most restrictive matches first. This is so that my value for “56.0 Feet” won’t be mistaken for “56.0 F” which would have it identified as a TEMP instead of LENGTH. (I should also be accounting for Celsius and Meters too but i am being lazy)
Let’s look a bit closer at a couple more of these regex.
(‘ASSIGN’, r‘: ‘), # Assignment operator
The assign operator is very important as we are going to use each instance of this to identify a rule that the NEXT token value should be ASSIGNED to the previous token value. The “little r” before the string means a “raw string literal”. Regex are heavy with “” characters, using this notation avoids having to do an escape character for everyone of them.
(‘DATETIME’, r‘(d+:(d+(:d)*)*)+s+(d+-d+-d+)‘), # Datetime value (ex. 00:00:00 12-12-2017)
Datetime is taking the numeric pattern I explained in detail above but slightly changing the “.” to a “:”. In my file, i want both 00:00 and 00:00:00 to match the time portion of the pattern, so therefore I use a nested “*” (remember that means 0 to n occurrences). The + at the end of the first section means at least 1 occurrence of the time portion, therefore simply a date field will not match this datetime regex. Then the “s” represents single or multiple line spaces (remember that regex is greedy and will keep taking spaces unless ended with “?”). Then the last section for the date will take any integer values with two dashes (“-“) in between. This means 2017-01-01 or 01-01-2017 or even 2017-2017-2017 would match the Datetime date section. This may be something I should clean up later 🙂
tok_regex = ‘|’.join(‘(?P<%s>%s)’ % pair for pair in token_specification)
I wanted to just quickly point out how cool it is that Python then allows you to take the list of regex specifications and separate them with a “|” by doing the “|”.join() notation. This will result in the crazy looking regex below:
‘(?P<SPEED_IN_OUT>(\d+(\.\d*)?/\d+(\.\d*)?\s{1}MPH))|(?P<SPEED>(\d+(\.\d*)?\s{1}MPH))|(?P<LENGTH>(\d+(\.\d*)?\s{1}Feet))|(?P<TEMP>(\d+(\.\d*)?\s{1}[F]))|(?P<DATETIME>(\d+:(\d+(:\d)*)*)+\s+(\d+-\d+-\d+))|(?P<TIME>(\d+:(\d+(:\d)*)*)+)|(?P<ID_W_NBR>(\d+(\.\d*)?\s([/\w]+\s?)+))|(?P<NUMBER>\d+(\.\d*)?)|(?P<ID>([/\w]+\s?)+)|(?P<ASSIGN>: )|(?P<NEWLINE>\n)|(?P<SKIP>[ \t]+)’
Two important things were done here. We gave each specification the ?P<name> notation which allows us to reference a match group by name later in our code. Also, each token specification was wrapped with parenthesis and separated with “|”. The bar is like an OR operator and evaluates the regex from left to right to determine match, this is why i wanted to put the most restrictive patterns first in my list.
The rest of the code iterates through the line (or string) that was given to find matches in using the tok_regex expression and yields the token value that includes the kind (or type) of the match found and the value (represented as value.strip() to remove the whitespaces from beginning and end).
Evaluating the Output
Now that our parser is defined, lets process the formatted file above. We add some conditional logic to skip the first line and any lines that have a length of zero. We also stop processing whenever we no longer encounter lines with “:”. This effectively is processing all headers and we will save the line processing for another task.
lines = list(csv.reader(open('truck01.txt',mode='r'),delimiter='t'))
counter = 0
ls = []
for l in lines:
if len(l)==0 or counter == 0:
counter += 1
continue
str = l[0]
index = str.find(":")
if(index == -1 and counter != 0):
break
print(str)
for tok in tokenize(l[0]):
print(tok)
counter += 1
The first few lines processed will result in the following output from the print statements (first the line, then each token in that line)
Site Name : Chicago IL Seq Number : 111
Token(typ=’ID’, value=’Site Name’, line=1, column=0)
Token(typ=’ASSIGN’, value=’:’, line=1, column=12)
Token(typ=’ID’, value=’Chicago IL’, line=1, column=14)
Token(typ=’ID’, value=’Seq Number’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’NUMBER’, value=’111′, line=1, column=59)
Mile Mrkr : 304.40 DB Index # : 171
Token(typ=’ID’, value=’Mile Mrkr’, line=1, column=0)
Token(typ=’ASSIGN’, value=’:’, line=1, column=12)
Token(typ=’NUMBER’, value=’304.40′, line=1, column=14)
Token(typ=’ID’, value=’DB Index’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’NUMBER’, value=’171′, line=1, column=59)
Direction : South Arrival : 00:02 09-22-2017
Token(typ=’ID’, value=’Direction’, line=1, column=0)
Token(typ=’ASSIGN’, value=’:’, line=1, column=12)
Token(typ=’ID’, value=’South’, line=1, column=14)
Token(typ=’ID’, value=’Arrival’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’DATETIME’, value=’00:02 09-22-2017′, line=1, column=59)
Speed In/Out: 33/18 MPH Departure : 00:03:45
Token(typ=’ID’, value=’Speed In/Out’, line=1, column=0)
Token(typ=’ASSIGN’, value=’:’, line=1, column=12)
Token(typ=’SPEED_IN_OUT’, value=’33/18 MPH’, line=1, column=14)
Token(typ=’ID’, value=’Departure’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’TIME’, value=’00:03:45′, line=1, column=59)
Slow Speed : 38 MPH Approach Speed : 0 MPH
Token(typ=’ID’, value=’Slow Speed’, line=1, column=0)
Token(typ=’ASSIGN’, value=’:’, line=1, column=12)
Token(typ=’SPEED’, value=’38 MPH’, line=1, column=14)
Token(typ=’ID’, value=’Approach Speed’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’SPEED’, value=’0 MPH’, line=1, column=59)
Approach Length: ~0.0 Feet
Token(typ=’ID’, value=’Approach Length’, line=1, column=42)
Token(typ=’ASSIGN’, value=’:’, line=1, column=57)
Token(typ=’LENGTH’, value=’0.0 Feet’, line=1, column=60)
Notice how everything is being parsed beautifully without having to do any counting of spaces or finding explicit header names. With being able to identify “SPEED”, “TIME”, “LENGTH”, we will also be able to write a function to change these to the proper type format and add a unit of measure column if needed.
The only assumptions we are going to make to process this header information are as below:
1. skip the first line
2. end processing when a non-empty line no longer has an assignment operator of “:”
3. pattern expected for each line is 0 to n occurrences of ID ASSIGN any_type
To handle #3 above, we add the below code to the end of the for loop shown above:
dict = {}
id = None
assign_next_value = False
for tok in tokenize(l[0]):
print(tok)
if tok.typ == "ASSIGN":
assign_next_value = True
elif assign_next_value:
dict = {id:tok.value}
print(dict)
ls.append(dict)
assign_next_value = False
id = None
dict = {}
else:
id = tok.value
If you follow the logic, we are just taking the string (each line of the file) and recording the value of the first token as the id, finding the assign operator “:”, and then recording the following token value as the value of a dictionary object. It then appends that dictionary to the “ls” list that was initialized in the first code snippet.
We could then format it as JSON by adding the below line of code after the for loop
import json
jsondata = json.dumps(ls,indent=2,seperators=(",",":"))
See output below, some additional formatting work needs to be done with this as well as pre-processing my numbers and date times to not be represented as strings, but that is not the focus of this blog post.
[
{
"Site Name":"Chicago IL"
},
{
"Seq Number":"111"
},
{
"Mile Mrkr":"304.40"
},
{
"DB Index":"171"
},
{
"Direction":"South"
},
{
"Arrival":"00:02 09-22-2017"
},
{
"Speed In/Out":"33/18 MPH"
},
{
"Departure":"00:03:45"
},
{
"Slow Speed":"38 MPH"
},
{
"Approach Speed":"0 MPH"
},
{
"Approach Length":"0.0 Feet"
},
{
"Amb Temp":"81 F"
},
{
"Battery Voltage":"12.03"
},
{
"Axles":"5"
},
{
"Truck Length":"56.0 Feet"
},
{
"Alarms":"0"
},
{
"Cars":"1"
},
{
"Integ Fails":"0"
},
{
"Gate A Cnt":"1"
},
{
"System Warn":"0"
},
{
"Gate B Cnt":"1"
},
{
"Weight":"72000"
},
{
"HBD Filter":"13 Point Median Filter"
}
]
Now What?
I hope to do a continuation of this blog post and explore a server-less architecture of taking the file from the FTP server, immediately running this pre-processing, and dumping the JSON out to a stream ingestion engine. From there, we can do all sorts of cool things like publish real time data directly to Power BI, or into a Big Data store. This follows principles of “Kappa Architecture”, a simplification of “Lambda Architecture” where everything starts from a stream and the batch processing layer goes away.
There are multiple ways to implement this, but with Cloud computing, we have an opportunity to do this entire chain of events in a “server-less” environment meaning no virtual machines or even container scripts have to be maintained. So, lets cover this next time
Conclusion
Regex are super powerful. I ignored them for years and now I feel super smart and clever for finding a better solution to file processing than i would have originally implemented without regex.
The full Python code from above as well as the formatted file can be found on my GitHub here