Power BI Audit Log Analytics Solution
As Power BI adoption in your organization grows, it becomes more and more important to be able to track the activity in the environment.
When you start to think about deploying a Power BI Audit Log solution that is repeatable there are a few challenges that you will face.
- Going to the O365 Audit Logs portal each time you want to extract log events is a manual process and doesn’t scale
- When automating this process through API or PowerShell, there is a limit to how much data you can pull, therefore examples that are currently available also don’t scale very well
- The AuditData field is a JSON format by default and although Power BI can parse JSON beautifully, when doing this over several thousand record entries may result in data load errors
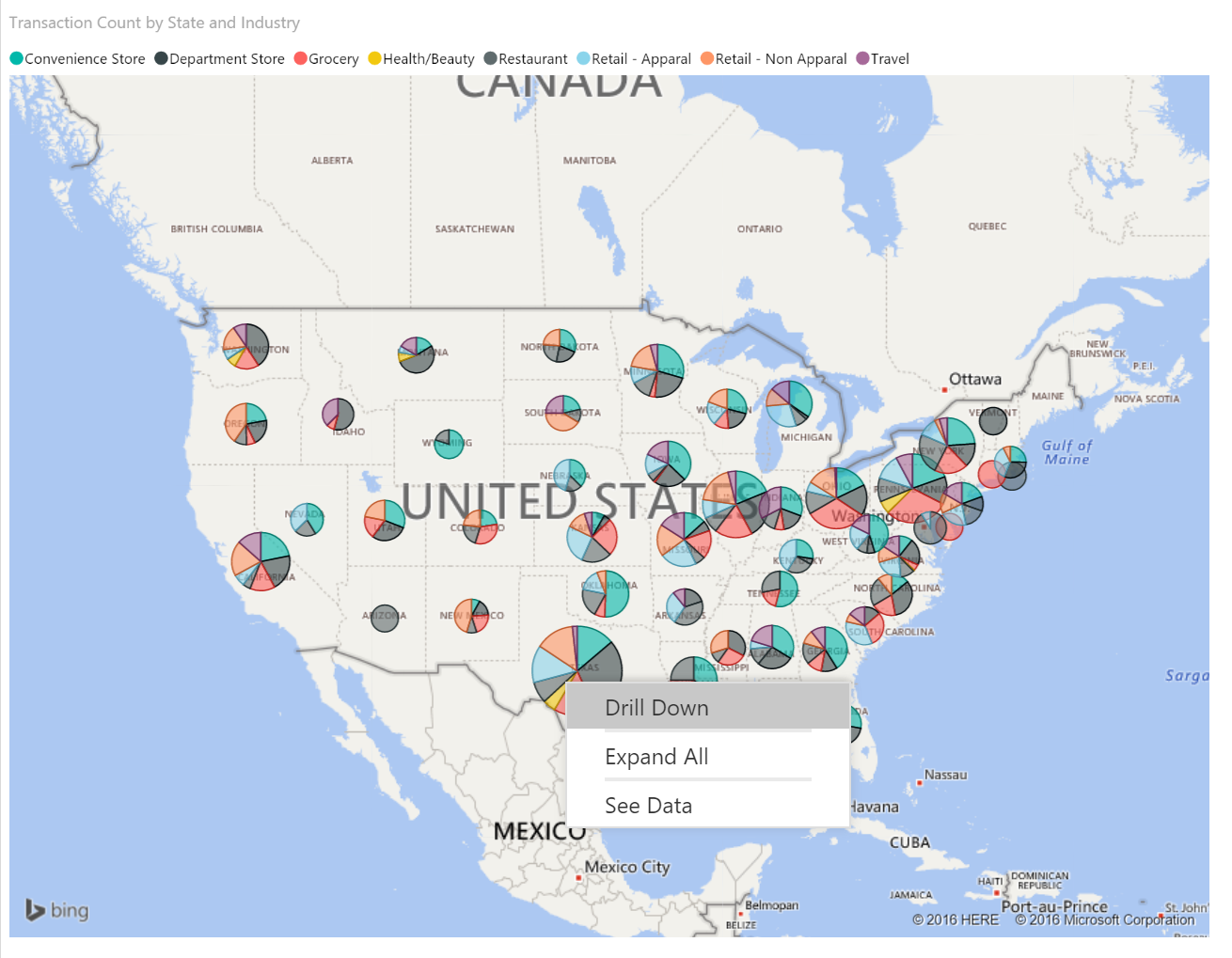
Based on these factors, i have put together a PowerShell script that can be scheduled on a nightly basis that can iterate MORE than 5000 records so that no data is lost. Also, the screenshot below is of an initial template that you can use to start with to analyze your audit logs for your organization.

TL;DR
.
- The required files can be found on my GitHub
- Update the PowerShell script with a UserID and Password that has O365 audit log privileges
- Use Task Scheduler to schedule the PowerShell script to run each night at midnight (run as admin).
- At the end of the script, specify the directory you would like the script to generate CSV files in
- In the PBIX file, it was challenging to get a parameter to work for the file location that the CSVs are in, so in the Query Editor the script for the AuditLog table needs to be manually modified to include your file path.
- Enjoy
Quick look at the PowerShell
First, there is a PowerShell script.
Set-ExecutionPolicy RemoteSigned
#This is better for scheduled jobs
$User = "<<enter o365 admin user email here>>"
$PWord = ConvertTo-SecureString -String "<<enter password here>>" -AsPlainText -Force
$UserCredential = New-Object -TypeName "System.Management.Automation.PSCredential" -ArgumentList $User, $PWord
#This will prompt the user for credential
#$UserCredential = Get-Credential
$Session = New-PSSession -ConfigurationName Microsoft.Exchange -ConnectionUri https://outlook.office365.com/powershell-liveid/ -Credential $UserCredential -Authentication Basic -AllowRedirection
Import-PSSession $Session
$startDate=(get-date).AddDays(-1)
$endDate=(get-date)
$scriptStart=(get-date)
$sessionName = (get-date -Format 'u')+'pbiauditlog'
# Reset user audit accumulator
$aggregateResults = @()
$i = 0 # Loop counter
Do {
$currentResults = Search-UnifiedAuditLog -StartDate $startDate -EndDate $enddate `
-SessionId $sessionName -SessionCommand ReturnLargeSet -ResultSize 1000 -RecordType PowerBI
if ($currentResults.Count -gt 0) {
Write-Host (" Finished {3} search #{1}, {2} records: {0} min" -f [math]::Round((New-TimeSpan -Start $scriptStart).TotalMinutes,4), $i, $currentResults.Count, $user.UserPrincipalName )
# Accumulate the data
$aggregateResults += $currentResults
# No need to do another query if the # recs returned <1k - should save around 5-10 sec per user
if ($currentResults.Count -lt 1000) {
$currentResults = @()
} else {
$i++
}
}
} Until ($currentResults.Count -eq 0) # --- End of Session Search Loop --- #
$data=@()
foreach ($auditlogitem in $aggregateResults) {
$datum = New-Object –TypeName PSObject
$d=convertfrom-json $auditlogitem.AuditData
$datum | Add-Member –MemberType NoteProperty –Name Id –Value $d.Id
$datum | Add-Member –MemberType NoteProperty –Name CreationTime –Value $auditlogitem.CreationDate
$datum | Add-Member –MemberType NoteProperty –Name CreationTimeUTC –Value $d.CreationTime
$datum | Add-Member –MemberType NoteProperty –Name RecordType –Value $d.RecordType
$datum | Add-Member –MemberType NoteProperty –Name Operation –Value $d.Operation
$datum | Add-Member –MemberType NoteProperty –Name OrganizationId –Value $d.OrganizationId
$datum | Add-Member –MemberType NoteProperty –Name UserType –Value $d.UserType
$datum | Add-Member –MemberType NoteProperty –Name UserKey –Value $d.UserKey
$datum | Add-Member –MemberType NoteProperty –Name Workload –Value $d.Workload
$datum | Add-Member –MemberType NoteProperty –Name UserId –Value $d.UserId
$datum | Add-Member –MemberType NoteProperty –Name ClientIP –Value $d.ClientIP
$datum | Add-Member –MemberType NoteProperty –Name UserAgent –Value $d.UserAgent
$datum | Add-Member –MemberType NoteProperty –Name Activity –Value $d.Activity
$datum | Add-Member –MemberType NoteProperty –Name ItemName –Value $d.ItemName
$datum | Add-Member –MemberType NoteProperty –Name WorkSpaceName –Value $d.WorkSpaceName
$datum | Add-Member –MemberType NoteProperty –Name DashboardName –Value $d.DashboardName
$datum | Add-Member –MemberType NoteProperty –Name DatasetName –Value $d.DatasetName
$datum | Add-Member –MemberType NoteProperty –Name ReportName –Value $d.ReportName
$datum | Add-Member –MemberType NoteProperty –Name WorkspaceId –Value $d.WorkspaceId
$datum | Add-Member –MemberType NoteProperty –Name ObjectId –Value $d.ObjectId
$datum | Add-Member –MemberType NoteProperty –Name DashboardId –Value $d.DashboardId
$datum | Add-Member –MemberType NoteProperty –Name DatasetId –Value $d.DatasetId
$datum | Add-Member –MemberType NoteProperty –Name ReportId –Value $d.ReportId
$datum | Add-Member –MemberType NoteProperty –Name OrgAppPermission –Value $d.OrgAppPermission
#option to include the below JSON column however for large amounts of data it may be difficult for PBI to parse
#$datum | Add-Member –MemberType NoteProperty –Name Datasets –Value (ConvertTo-Json $d.Datasets)
#below is a poorly constructed PowerShell statemnt to grab one of the entries and place in the DatasetName if any exist
foreach ($dataset in $d.datasets) {
$datum.DatasetName = $dataset.DatasetName
$datum.DatasetId = $dataset.DatasetId
}
$data+=$datum
}
$datestring = $startDate.ToString("yyyyMMdd")
$fileName = ("c:PBIAuditLogs" + $datestring + ".csv")
Write-Host (" writing to file {0}" -f $fileName)
$data | Export-csv $fileName
Remove-PSSession -Id $Session.Id
- Notice that you need to enter O365 audit log privileged credentials at the top so that this can be ran automatically. If you have more clever ways to pass these credentials in so they are not exposed in the file by all means, do that
- The Do/Until loop handles if there are more than 5000 records in the result set which would easily be the case for a large Power BI community.
- The foreach loop extracts the AuditData column JSON format and creates an individual record for each entry. This makes the Query Editor in Power BI less complex and easier to accomplish retrieving several hundred thousand records without import errors
- finally we create a CSV for the data with the date of the file entries (yesterdays info if this is ran at midnight every day). This dumps each file in c:PBIAuditLogs. You can obviously change this file location to wherever you want to store your CSV extracts

You can use Task Scheduler to run the above PowerShell script every night at midnight.
The PBIX file
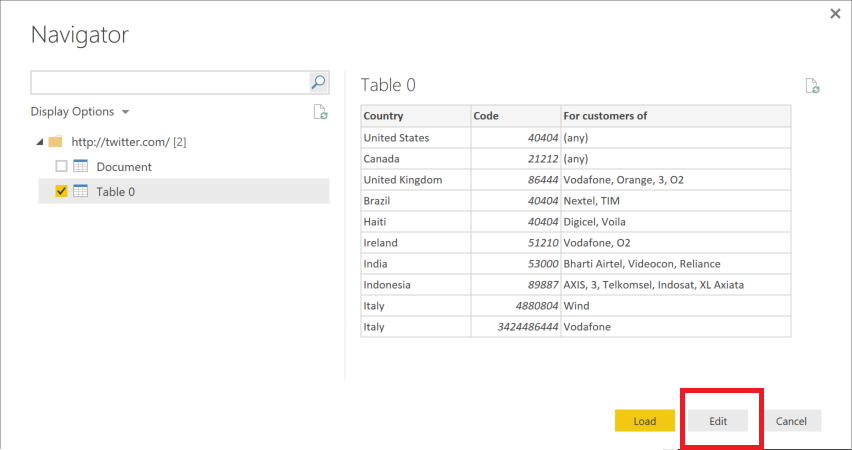
In the Power BI file, we are connecting to the content of the entire folder shown above. I went ahead and included the PBIX file WITH the sample data so you could get an idea of what your data may look like.
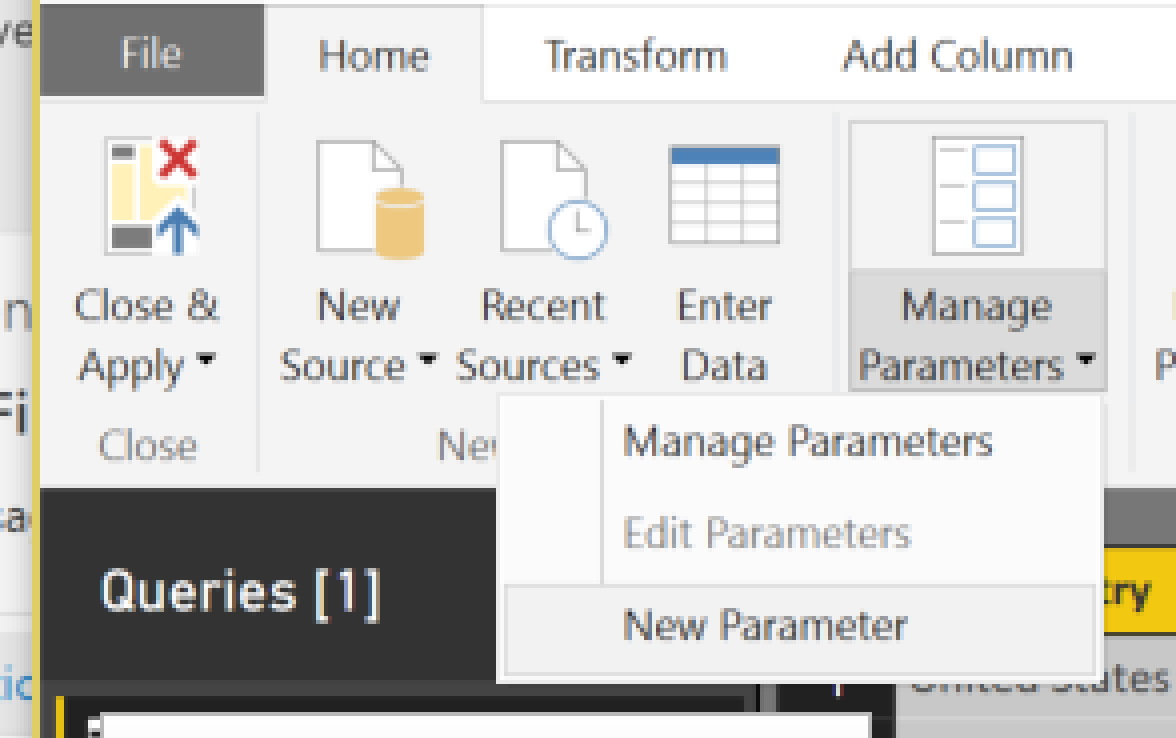
This is where i have to admit that i tried to use a parameter for this but ran into some Query Editor challenges with how Power BI creates a Sample File transform to import multiple files from a single folder. If you can see what i did wrong here I would love your feedback, but for now, you can ignore the file directory parameter in the Query Editor and need to go to “Advanced Editor” on the “AuditLog” query and modify the file location to be the location you are dumping files from the PowerShell script.

Change the below file location as needed.

Once you have made this change, you should be able to “Close and Apply” and your data will now be populated in this basic audit log analytics view.
Using the file
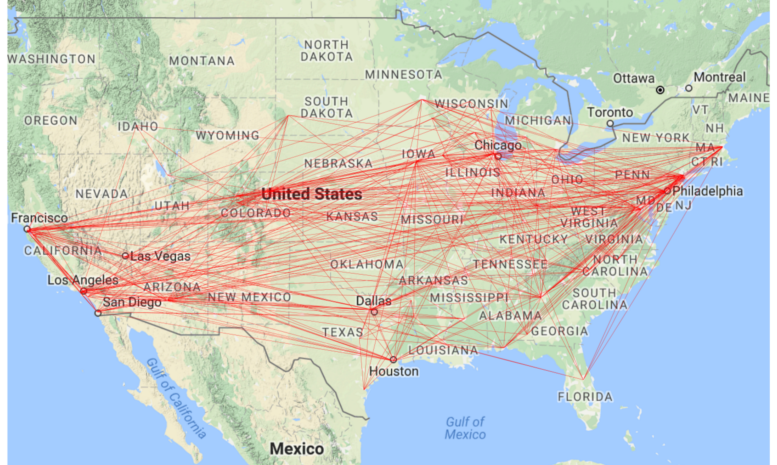
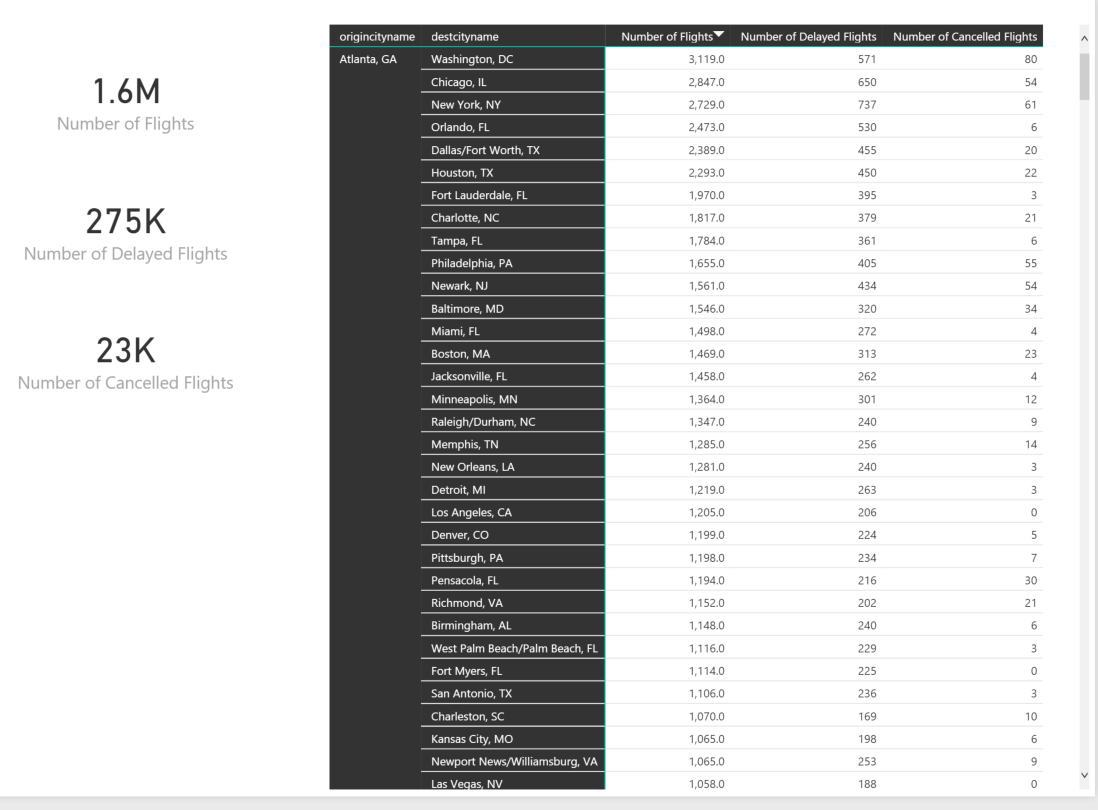
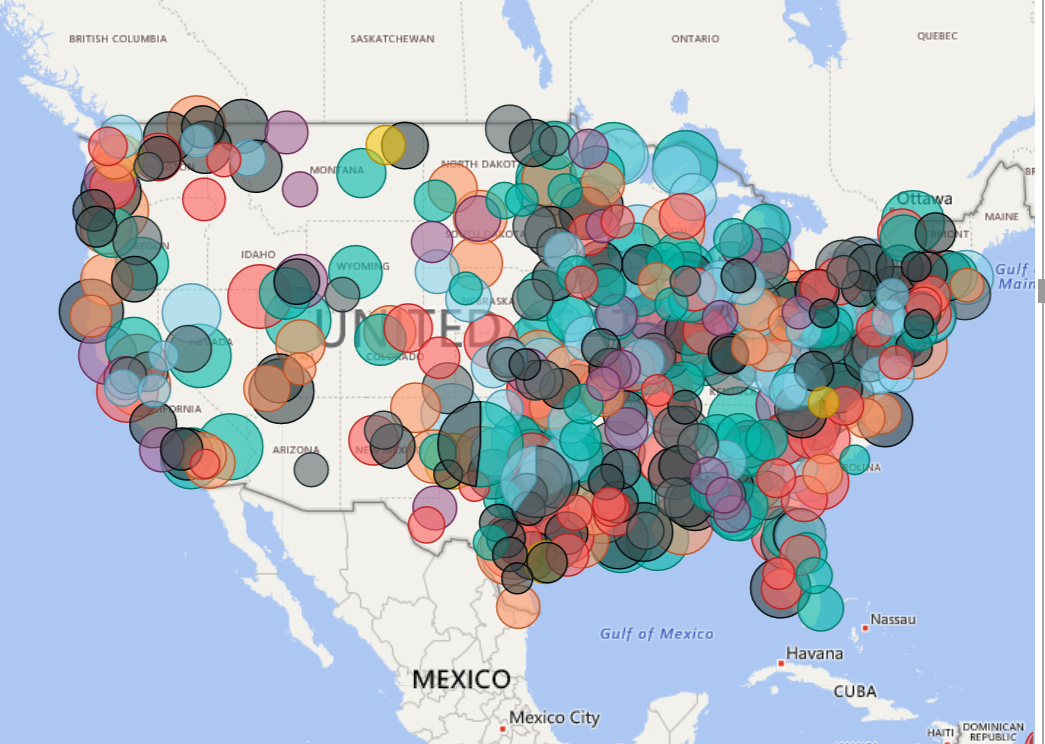
I created a couple basic pages to get this blog post shipped and so you can start taking advantage of the solution, but it is nowhere near as complete as you can eventually make it. I have a simple overview page that was screenshotted above. It can help you determine number of active users, reports, dashboards, and datasets being used for any time period your audit log data covers.
The second page is a user activity view i created from a calculated table. It helps you determine which users in the system may be inactive so you can re-assign power bi licenses and also shows detailed activity for an individual user that you can select from the slicer.

Other things you can mine from this data:
- Who has signed up for Free Power BI trials
- What “Apps” are being created
- what embed tokens are being generated and used
- many other possibilities
The PowerShell script and the PBIX file are located on my GitHub here…