Most organizations are trying to move to cloud for advanced analytics scenarios, but they have one big problem: They have invested a decade in an on premises data warehouse that has too much spaghetti architecture around it to untangle. I will discuss full migration options in Part 2 of this blog post, but will be focused in this article about using Azure Data Factory to keep an on prem DW (whether that is Teradata, Netezza, or even SQL Server) synchronized to Azure SQL DW on a nightly basis. Synchronization is important because it will allow all of your “new development” to happen in the cloud while allowing the 12-24 months that you may need to do a true DW migration project to pull the legacy connections to the new environment.
This article is going to assume at least some basic understanding of Azure Data Factory V2 (ADF). It is also a good idea to be familiar with this documentation on copying data to and from Azure SQL DW with ADF.
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-data-warehouse
TL;DR
This post focuses on most difficult part of data synchronization: dealing with updates! Most data warehouses still see updated records and the ADF templates provided for “delta loads” only deal with inserts. On my github https://github.com/realAngryAnalytics/adf I have provided an ARM Template that can be imported that includes the control tables and stored procedures needed to make this work.
Azure Data Factory V2 and Azure SQL DW Gen 2
These products have matured over the last couple of years so much that it has made me (an analytics guy) excited about data movement and data warehousing. With the addition of Mapping Data Flows https://docs.microsoft.com/en-us/azure/data-factory/data-flow-create ADF now has a real transformation engine that is visually aesthetic and easy to use. I have also found when using SQL DW Gen 2 my Direct Query times from tools like Power BI have significantly decreased and starts to make Direct Query a real option for BI tools.
All you need is 3 pipelines!
Of course, the devil is always in the details, however for most large enterprise data warehouses, these 3 pipelines should cover 98% of your scenarios. You may need a custom pipeline here or there but the idea is to write 3 generic pipelines and use control tables and parameters to handle 100s or 1000s of tables.
- Initial Data Load (will discuss in Part 2, but template can be found here: https://docs.microsoft.com/en-us/azure/data-factory/solution-template-bulk-copy-with-control-table
- Small table truncate and reload (will discuss in Part 2, but by far the easiest of the three)
- Delta loads including updates (the focus of this post)
Delta Loads and dealing with updates
In this post, we will deal with the most difficult part of data synchronization which is updated records in a delta load. Azure Data Factory provides a template for delta loads but unfortunately it doesn’t deal with updated records.
Delta load template:
https://docs.microsoft.com/en-us/azure/data-factory/solution-template-delta-copy-with-control-table

Accompanying this blog post is my GitHub repository https://github.com/realAngryAnalytics/adf where you will find all the resources needed to perform the below example.
Example Dataset
This example uses an Azure SQL Database with Adventure Works DW 2016 installed. Can be downloaded here: https://www.microsoft.com/en-us/download/details.aspx?id=49502
We are using the FactResellerSales table and will do an initial sync to Azure SQL DW and then perform inserts and updates on the source dataset and see them properly be reflected.
Source Database Prep
Run the data prep script:
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/sourcedatabaseprep.sql
Two main things are occurring here:
- Create a new schema called [ANGRY] in the source database, create FactResellerSales table and copy original data here so that we do not disturb the original sample tables that you may want to use for something else later.
- Alter table to add a “ModifiedDate” and initially populate with the original OrderDate
Must have Modified Dates on Delta Load tables
This is the one prerequisite you will have on your data warehouse. Tables that you are unable to truncate and reload are going to be Fact/Transactional type tables and there should usually be a Modified Date concept. But sometimes there is not and that is an effort that will need to be made to make this work.
Destination Database Prep
The syntax in the below data prep script is for Azure SQL DW. There are some SQL differences from a standard SQL Server. Keep that in mind.
Run the data prep script:
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/destdatabaseprep.sql
There is a lot going on in this script and worth reviewing. The basic stuff is as follows:
- Creating new [ANGRY] schema (as done in source also)
- Creating watermark table and update_watermark stored procedure (explained in detail in the base delta load template: https://docs.microsoft.com/en-us/azure/data-factory/solution-template-delta-copy-with-control-table)
- Populate watermark table with initial date to use (1/1/1900 will mean our first pipeline run will replicate all data from FactResellerSales source to the destination SQL DW).
- Create FactResellerSales table (alter with ModifiedDate)
How to handle updates
To perform updates most efficiently you should have a Staging table for every table that will be doing delta loads. It will have an identical DDL to the actual table (FactResellerSales) except it will be a HEAP table
There will also be a delta control table that will contain the primary key columns that will determine uniqueness of a record for each table. My implementation handles up to 6 key columns. If you have more, you will have to modify the table and stored procedure.
Note: Being able to handle a multi column unique constraint is very important to handle source DWs such as Teradata.
/* This is specific to the concept of being able to handle delta loads
that may contain updates to previously loaded data */
CREATE TABLE [ANGRY].[deltacontroltable](
[TableName] [varchar](255) NULL,
[WatermarkColumn] [varchar](255) NULL,
[KeyColumn1] [varchar](255) NULL,
[KeyColumn2] [varchar](255) NULL,
[KeyColumn3] [varchar](255) NULL,
[KeyColumn4] [varchar](255) NULL,
[KeyColumn5] [varchar](255) NULL,
[KeyColumn6] [varchar](255) NULL
)
WITH
(
CLUSTERED INDEX (TableName)
);
GO
/* Insert into deltacontroltable the metadata about the destination table and the key fields that are needed to
get a unique record. For FactResellerSales this is SalesOrderNumber and SalesOrderLineNumber */
INSERT INTO ANGRY.deltacontroltable
values ('ANGRY.FactResellerSales','ModifiedDate','SalesOrderNumber','SalesOrderLineNumber',null,null,null,null);
Our FactResellerSales table requires two keys to determine uniqueness: “SalesOrderNumber” and “SalesOrderLineNumber”. The insert statement is included in the code above.
Non used key columns are left null. I also have a WatermarkColumn in my implementation however I did not determine a need for it so it could be omitted.
The Magic Stored Procedure
The delta_load_w_updates stored procedure (in the destdatabaseprep.sql script linked above) uses the control table, sink table and staging table to build a dynamic sql that will delete records from the sink data source if they exist, and then insert all records from the staging table in bulk. Note that an example of the generated SQL below doesn’t use an INNER JOIN directly in the DELETE as SQL DW will not support it.
/* Example output of the stored procedure */ DELETE ANGRY.FactResellerSales WHERE CAST(SalesOrderNumber as varchar(255)) + '|' + CAST(SalesOrderLineNumber as varchar(255)) IN (SELECT CAST(t2.SalesOrderNumber as varchar(255)) + '|' + CAST(t2.SalesOrderLineNumber as varchar(255)) FROM ANGRY.FactResellerSales_Staging t2 INNER JOIN ANGRY.FactResellerSales t1 ON t2.SalesOrderNumber = t1.SalesOrderNumber AND t2.SalesOrderLineNumber = t1.SalesOrderLineNumber)
With a stored procedure that does the above DELETE and INSERT based on records that already exist and INSERT all the data that has a modified date greater than the last watermark, we can now move on to the ADF pipeline nuances to consider between the base delta load template and this new version that will handle updates.
Deploy the Data Factory
First we will deploy the data factory and then we will review it.
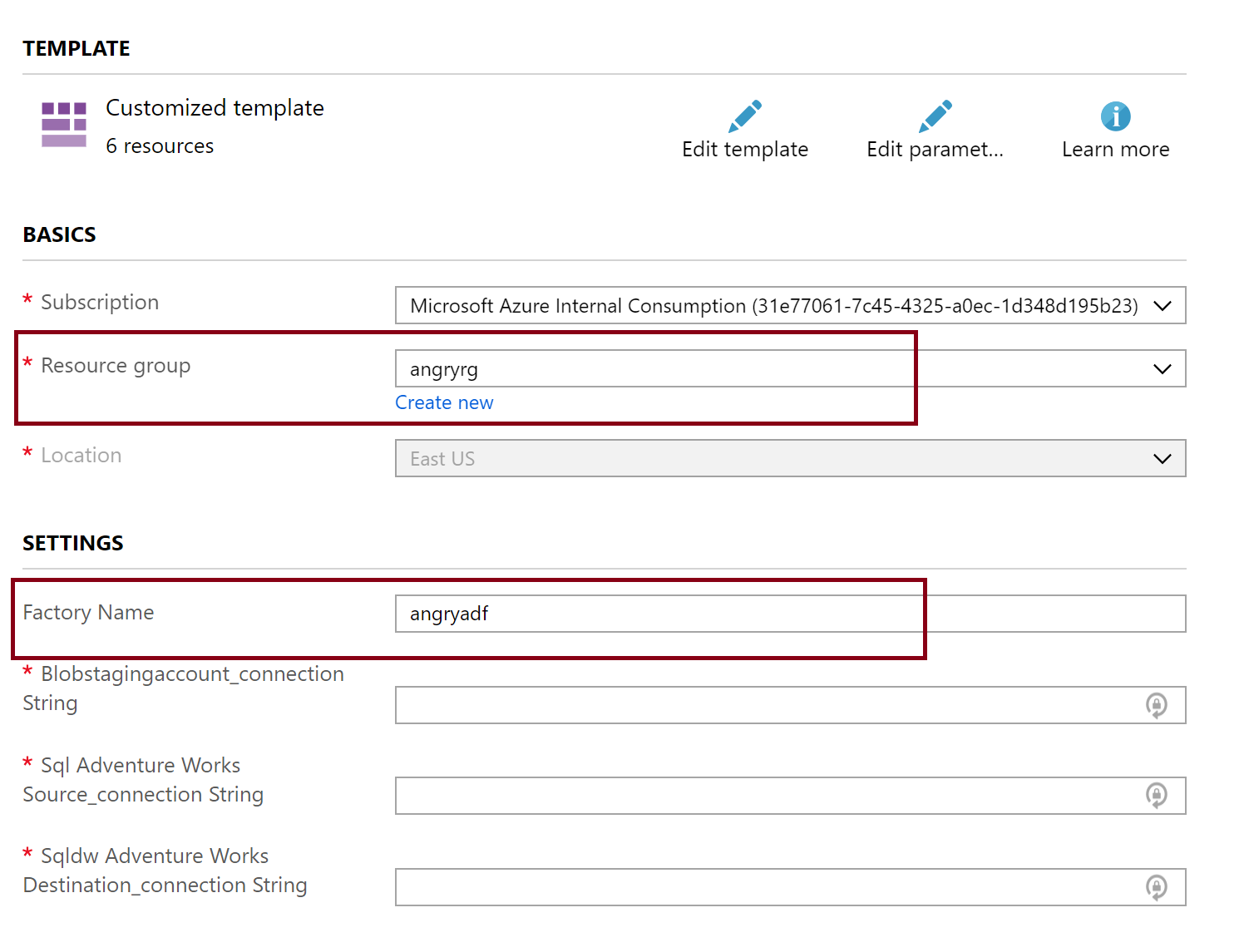
In the Azure Portal (https://portal.azure.com), create a new Azure Data Factory V2 resource. I named mine “angryadf”. Remember the name you give yours as the below deployment will create assets (connections, datasets, and the pipeline) in that ADF.
The button below will deploy the data factory assets including the delta_load_w_updates pipeline. Note: it will fail if you haven’t created the data factory yet

This is a template that requires three connection strings:
- Blob storage account connection string – will be used for staging the load to SQL DW. This can be found in your “Keys” dialog of your blob storage account
- Source azure sql database connection string – will be the source. Found in “settings -> Connection Strings” dialog. Using SQL Authentication is probably easiest. Replace “User ID” and “Password” entries with your real values or the deployment will fail.
- Even if you choose to use Teradata or Netezza or SQL on prem for the source, go ahead and use an azure sql database so that the template deploys, then you can modify the source. (it will cost you $5 a month)
- Destination azure sql data warehouse connection string – will be the destination. Just like Azure SQL DB, it is found under “settings -> Connection Strings” dialog. Don’t forget to change your User ID and Password entries
Or from https://adf.azure.com you can import the azuredeploy.json file (ARM Template) from the root of my github https://github.com/realAngryAnalytics/adf/blob/master/azuredeploy.json
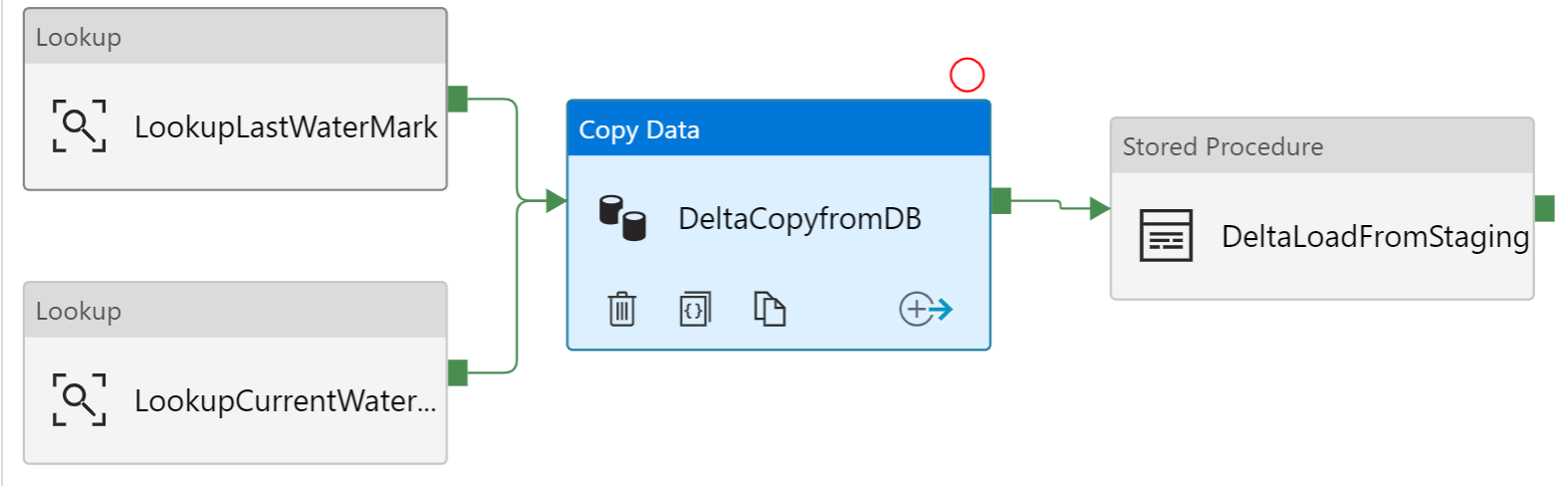
Review the Pipeline
This pipeline is based on the original delta load template so I will only review the main differences I have implemented.
Note: In the below screenshots there is liberal use of parameters and if you are not familiar with the “Add Dynamic Content” feature it may look more difficult than it is. Using “Add Dynamic Content” allows you to construct expressions visually. See more about expressions here.
Using Parameters to pass into the pipeline is how you can keep it generic to work with any delta load. I have added defaults to all of them to work with this example and one additional parameter has been added for the destination staging table:

In the copy activity, instead of inserting directly to the same table in the sink, it is inserting into the staging table.

Note: As you can see from the above screen shot, I also prefer to parameterize the table name for the source and sink dataset objects. ADF has a bad habit of creating individual datasets for every table which gets out of control. The use of a TableName parameter allows you to create one source dataset and one sink dataset.
Also on the copy activity, there is a pre-copy script action that is going to truncate the staging table before every run. This means that after each run the records are left in the staging table (presumably for a day) to investigate for any errors until the next time the pipeline runs and truncates the rows before inserting the next day’s records.

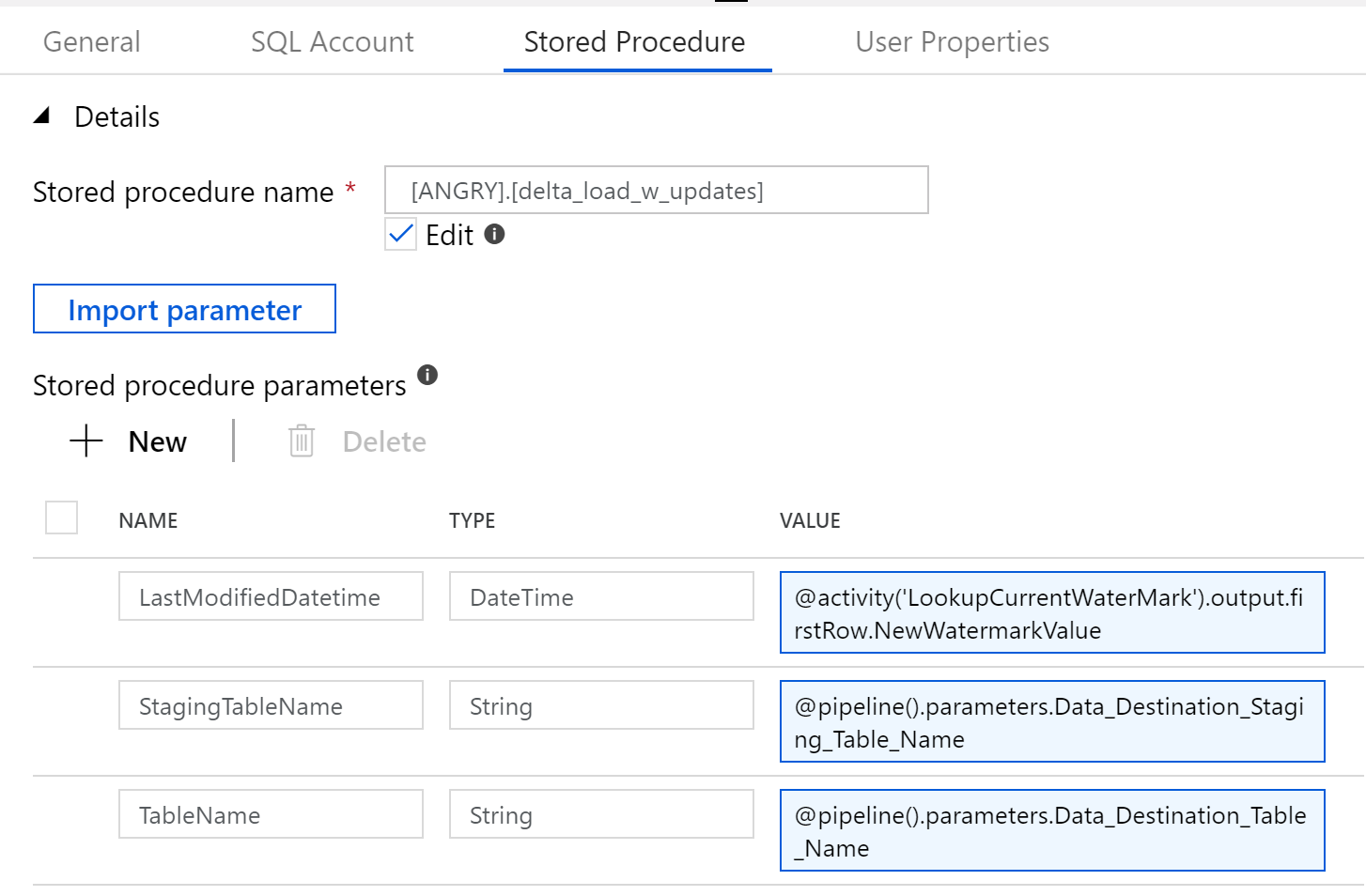
Lastly the stored procedure activity I have changed from the original that just updated the watermark table to the delta_load_w_updates procedure we created above. This procedure does the work to move from staging to the main table and then updates the watermark table inline.
Initial Run (initial load of all data to SQL DW)
In the pipeline, ensure it is valid by clicking “Validate” check box and after fixing any errors click “Debug”.
Note: Default values for all pipeline parameters are entered. If you changed the schema name or used a different table, these will have to be modified.

As you are debugging you will get an output for each activity. In the “Actions” column you can retrieve the inputs, outputs, and look at the details of the copy activity by clicking on the glasses icon.
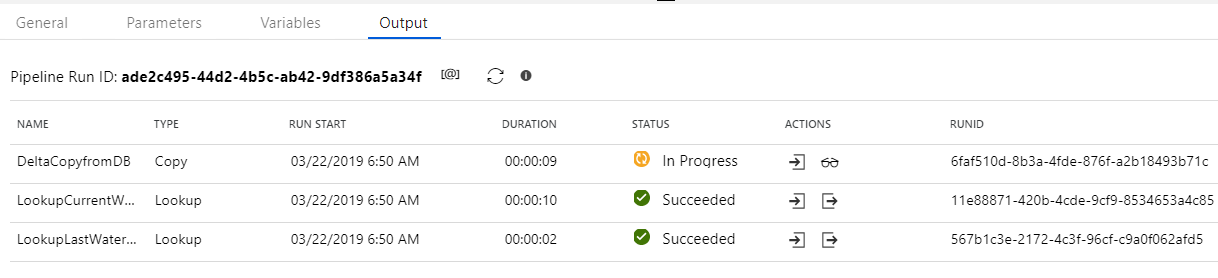
Details of the copy activity:
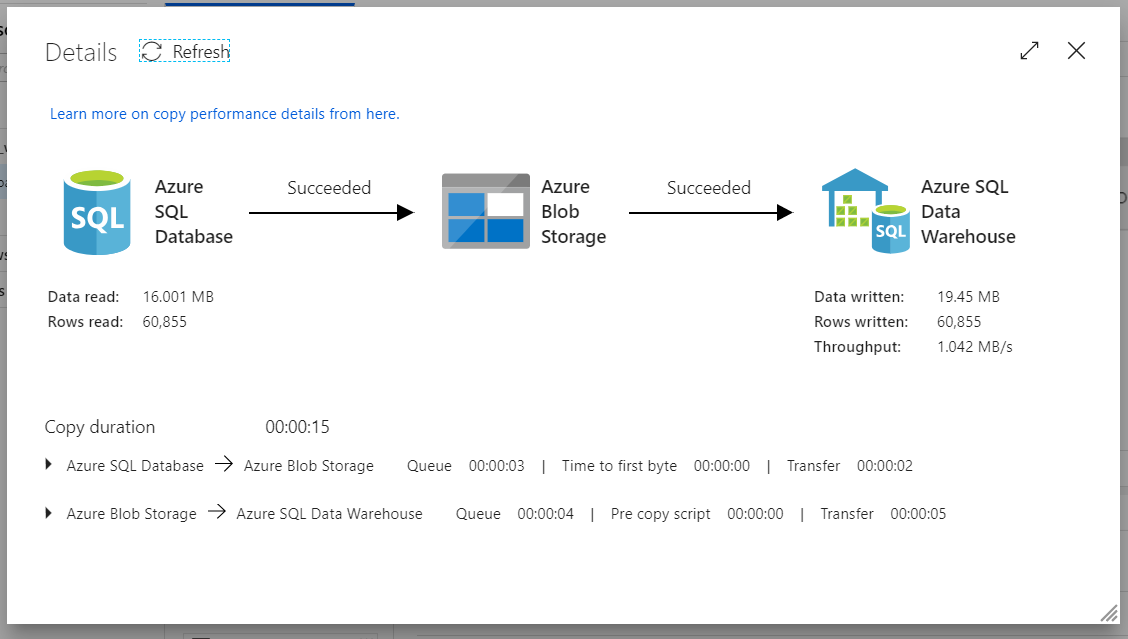
You can run the below SQL statements to see that all rows have been copied to the staging table and then to the main table and that the watermark table has been updated with the MAX ModifiedDate in the source (which happens to be 11/29/2013 for my old AdventureWorks dataset)
select count(*) from [Angry].[FactResellerSales] select count(*) from [Angry].[FactResellerSales_Staging] select * from [Angry].[watermarktable]
Insert and Modify records in the source
Run the below script to create a very basic adventure works FactResellerSales data generator that takes the first input as number of inserted records and second input as number of updated records you want to use.
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/advworks_datagenerator.sql
So let’s synthetically create 1000 new records and 500 modified records against the source dataset.
exec ANGRY.sp_generate_advworks_data 1000, 500
Verify the creation of new and modified records in the source dataset.
/* First query retrieves the inserts, second query retrieves the updates, third query should be total */ select count(*) from ANGRY.FactResellerSales where OrderDateKey = 0; select count(*) from ANGRY.FactResellerSales where OrderQuantity = 42; select count(*) from Angry.FactResellerSales where ModifiedDate = (select MAX(ModifiedDate) from ANGRY.FactResellerSales);
Note: The purpose of this example is to demonstrate capability, not to have realistic data, so all inserted records have zeros for nearly all the integer values and the updates simply updated the OrderQuantity to 42.
Run the pipeline again. Note you can review the outputs of the first two lookup activities by clicking on the actions icon below.

Below, the first value is last watermark (retrieved from the watermark table) and the second value is the current watermark (retrieved from the max value in the source table)
{ "firstRow":
{ "TableName": "ANGRY.FactResellerSales",
"WatermarkValue": "2013-11-29T00:00:00Z" },
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US 2)" }
{ "firstRow":
{ "NewWatermarkValue": "2019-03-26T19:56:59.29Z" },
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)" }
The copy activity is going to retrieve everything from the source table between these two dates based on the source SQL that is being constructed in the “Query” field.

Reviewing the copy activity details, you should see 1500 records
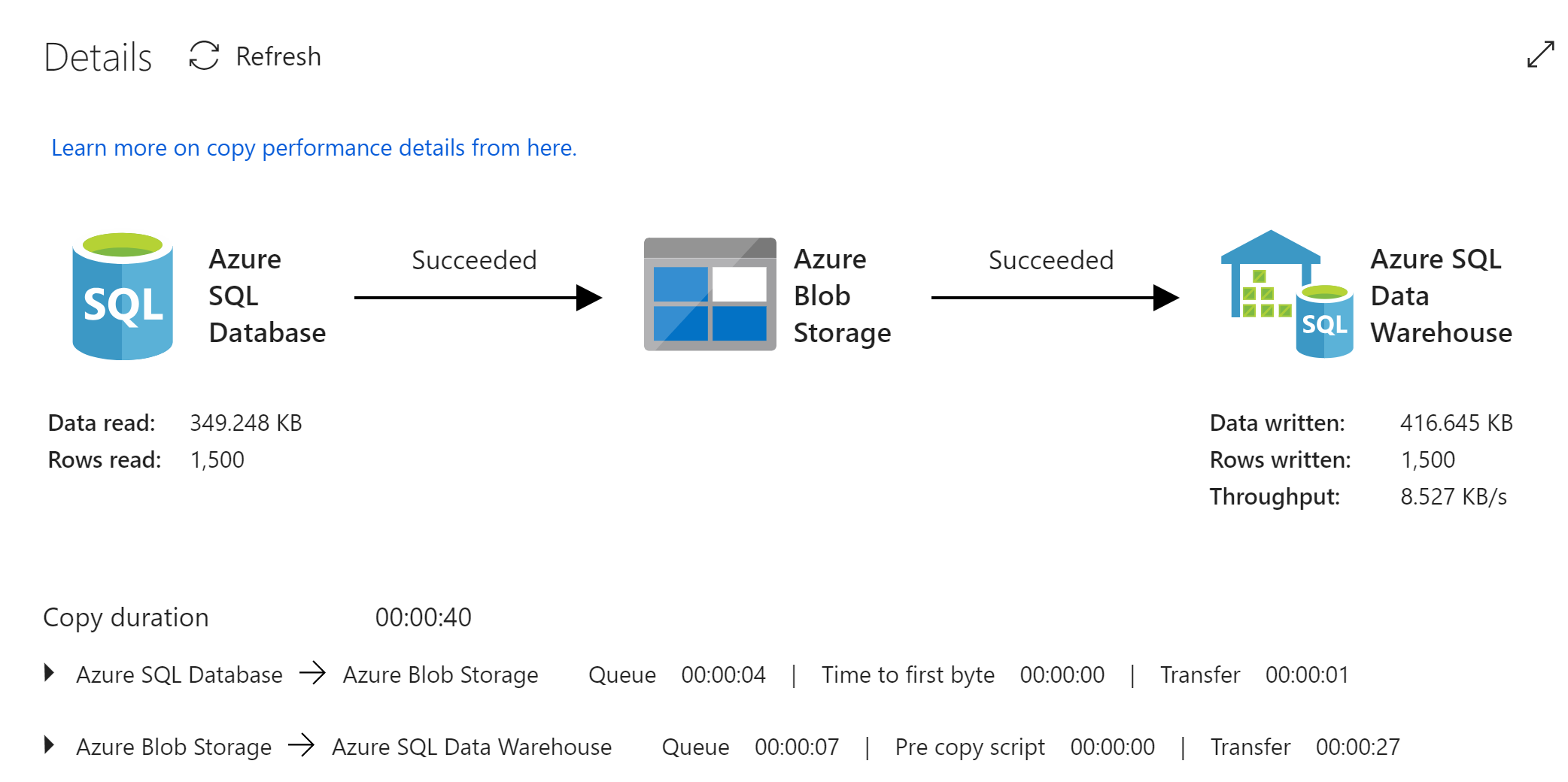
Run the same queries you ran against the source table now against the staging table to see the inserted and modified records.
Unfortunately there is not a pretty view of what happened in the stored procedure activity. All we can see are the inputs and outputs as shown below:
{ "storedProcedureName": "[ANGRY].[delta_load_w_updates]",
"storedProcedureParameters":
{ "LastModifiedDatetime":
{ "value": "2019-03-26T19:56:59.29Z",
"type": "DateTime" },
"StagingTableName":
{ "value": "ANGRY.FactResellerSales_Staging", "type": "String" },
"TableName": { "value": "ANGRY.FactResellerSales", "type": "String" }
}
}
{ "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US 2)",
"executionDuration": 4239 }
To implement this in production you will probably want to harden the stored procedure by adding transaction/rollback and some validation output.
Nonetheless, you should see in your destination table (by running the same queries as above) that you have successfully inserted 1000 records and updated 500 existing records.
Congratulations, you now have SQL code and an ADF pipeline that handles the hardest part of syncing a data warehouse to the cloud which is dealing with updates.

How does this change if source is Teradata or Netezza?
This example used a SQL source, however not too much should change with Teradata or Netezza. Double check the query syntax for your source, but both the “LookupCurrentWatermark” activity as well as the “DeltaCopyFromDB” activity should both be standard T-SQL, but nonetheless, worth checking if you have errors.
One thing to triple make sure however is that in the “DeltaCopyFromDB” activity under the sink tab that “Use Type default” is NOT checked.
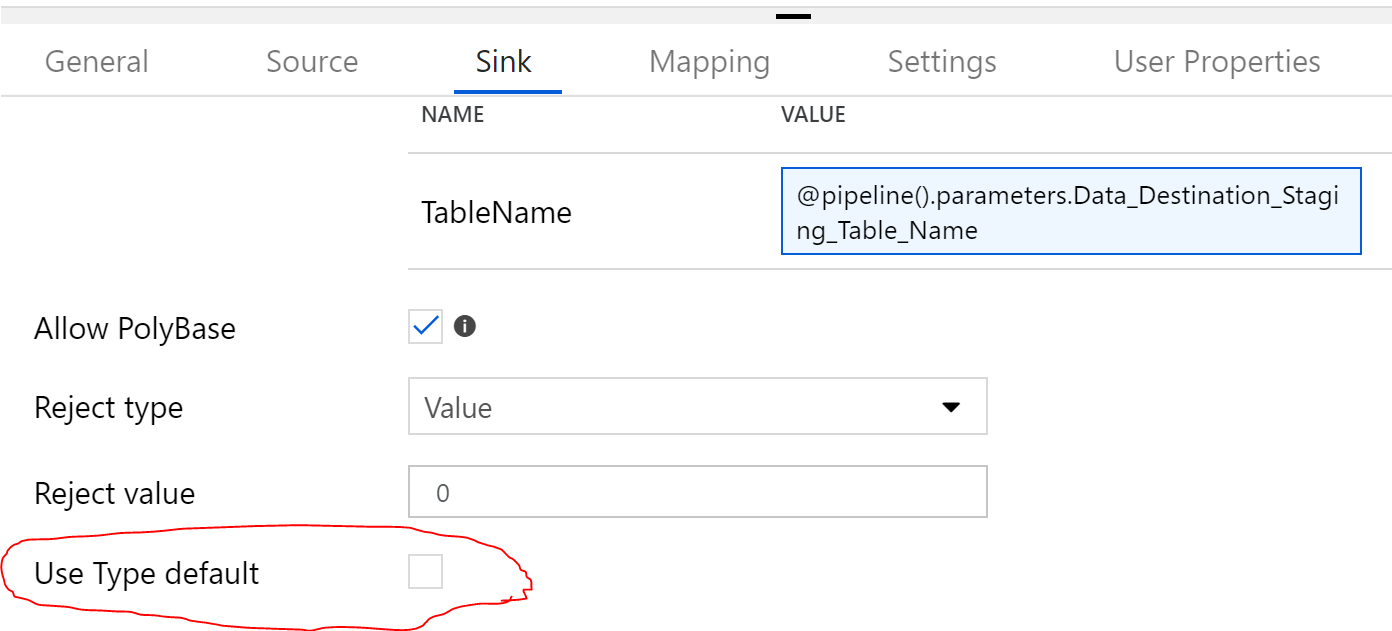
In SQL Server, this doesn’t seem to matter but when copying null values for numeric fields from Teradata, this will cause polybase to error out with an “empty string cannot be converted to a decimal” error.
Expanding to 100’s of tables
So we have only done this for one table yet I say that with this pipeline and two others I can sink an entire data warehouse. If you are familiar with ADF (which you have to be if you endured this entire article) than you know you can create Triggers with different input parameters to handle different tables. For each new table you want to do delta loads it will require an entry in the deltacontroltable as well as a new staging table. This is simply the cost of doing business to achieve cloud success. This is fairly straight forward data entry work or through a couple days of scripting you can automate it.
One other thing to note, if you are sinking a data warehouse, remember that the source DW is downstream from existing ETL processes. Now we are adding on additional processing that needs to be completed at the end of your existing nightly loads. So even though you could create 100s of scheduled triggers in ADF with the different parameters required for each delta load, more realistically you are going to want to kick off the delta load pipeline as an event as soon as that table is loaded into the source DW. This can be achieved with the ADF APIs
Next in Part 2
Handling updates in ADF was the part of this I really wanted to cover as it seems to be what everyone struggles with. However, there are two other pipelines that are needed to complete the synchronization scenario, so I will cover those in a little more depth based on my experience. If I would have done this in logical order I would have started with the bulk load but I am not logical.
I also want to discuss how to pull forward all of your legacy integrations with your on prem DW.

ADF Dataflows make this super simple without all the stored procedure mess.
LikeLike
Agree. I really enjoy using Azure Data Flows and it makes ADF a full fledged ETL tool. But I would challenge you to write an Azure Data Flow that is dynamic enough to handle 100s of different table structures and unique constraint combinations as I have in the stored procedure. Sometimes writing code is just easier. But if a Data Flow works for your scenario by all means use them.
LikeLike
I am new to ADF. I really enjoyed your post. I am interested in part 2
truncate/reaload. I have 10 very small dim tables that I like to refresh it nightly in one pipeline.
LikeLike